[호붕싸 모각코 12차] Recurrent Neural Networks
| 작성자 | 배세은 |
| 소 감 | 오늘은 RNN을 복습해보았다. 예전부터 많이 했던 내용이라 어렵지 않게 정리할 수 있었다. |
| 일 시 | 2025. 5. 23. (금) 18:00 ~ 21:00 |
| 장 소 | 미래관 429호 자율주행스튜디오 |
| 참가자 명단 | 신수민, 임혜진, 배세은, 김윤희 (총 4명) |
| 사 진 |  |
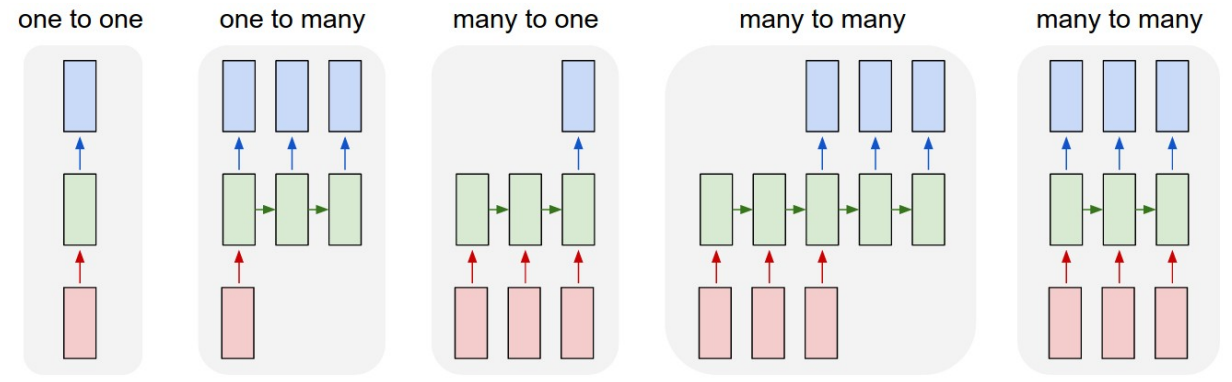
RNN의 네트워크들이다. 왜냐면 input이나 output에 순차성이 존재하기 때문이다. (one to one빼고, 이건 그냥 NN임)
우선 헷갈리면 안되는게 항상....시간에 따른 변화지 그림에 있는게 특정 시간에 저렇게 생겼다고 착각하면 안되는거임 근데 나는 항상 왜 헷갈리는지 모르겟삼

매 타임스텝마다 x인풋을 받고 y인풋을 내뱉는 형태로 이루어져있고, h가 있는데 이는 매 타임 스텝마다 이전의 hidden state와 현재의 x를 받아 어떤 모델 w를 거쳐 새로운 hidden state로 갱신된다.
여기에서 중요한 점은! 매 step마다 같은 function과 같은 w를 사용한다는 점이다. 후에 backprop을 하면서 달라지겠지..?

식을 자세히 알아보자미연! 우선 현재 hidden state를 만드려면 2개의 입력이 필요하다고 했죠? 그럼 2개의 각 입력을 계산할 w가 필요하겠죠? 그래서 이전 hidden state와 계산할 w(Whh) 1개, 현재 input과 계산할 w(Wxh) 1개가 필요합니다람쥐 여기에 bias더하고 두 개 더해서 tanh씌워줌요 이렇게 현재 hidden state 계산 완
그리고 이렇게 만들어진 hidden state에서 output을 뽑아낼건데 이때 씌여질 w(Why ...엥 why?가 아니라 가중치임;)도 한 개 필요하다.
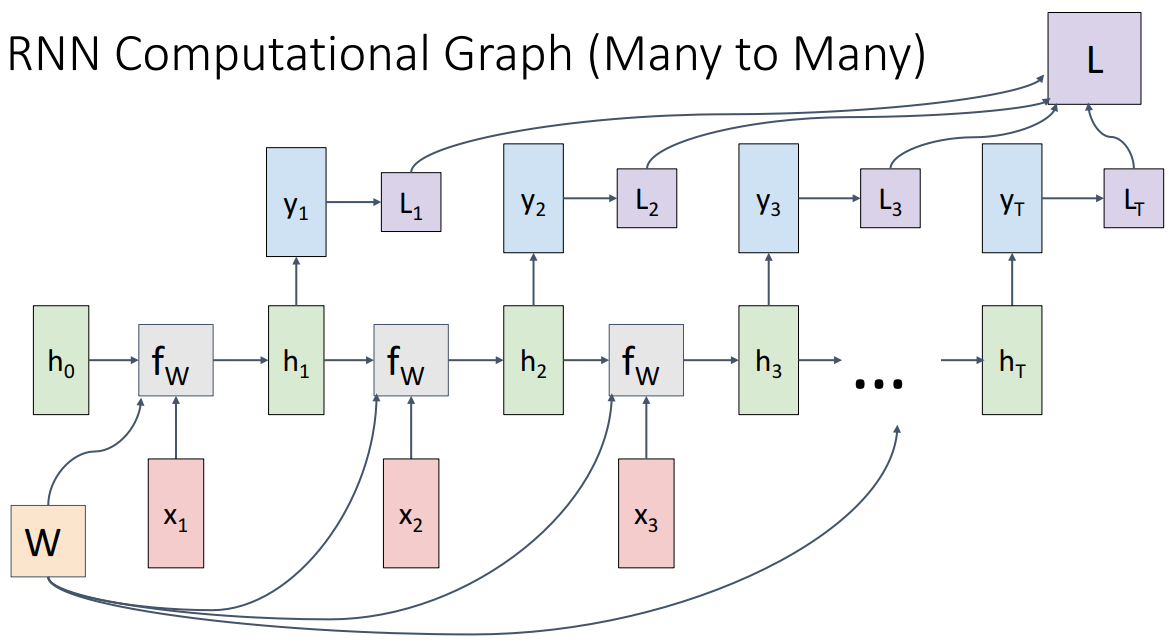
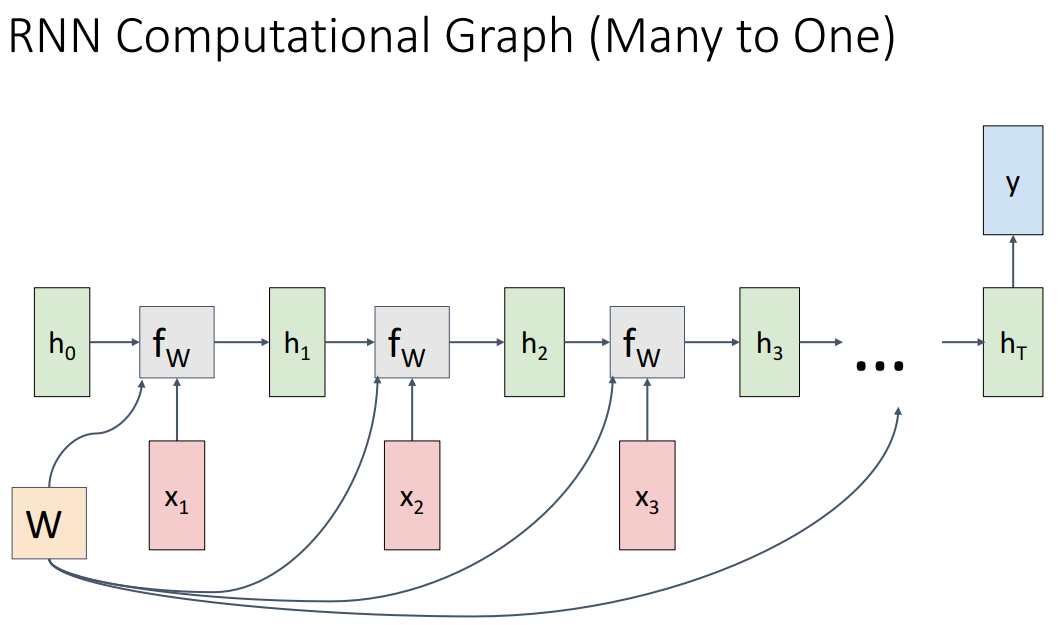
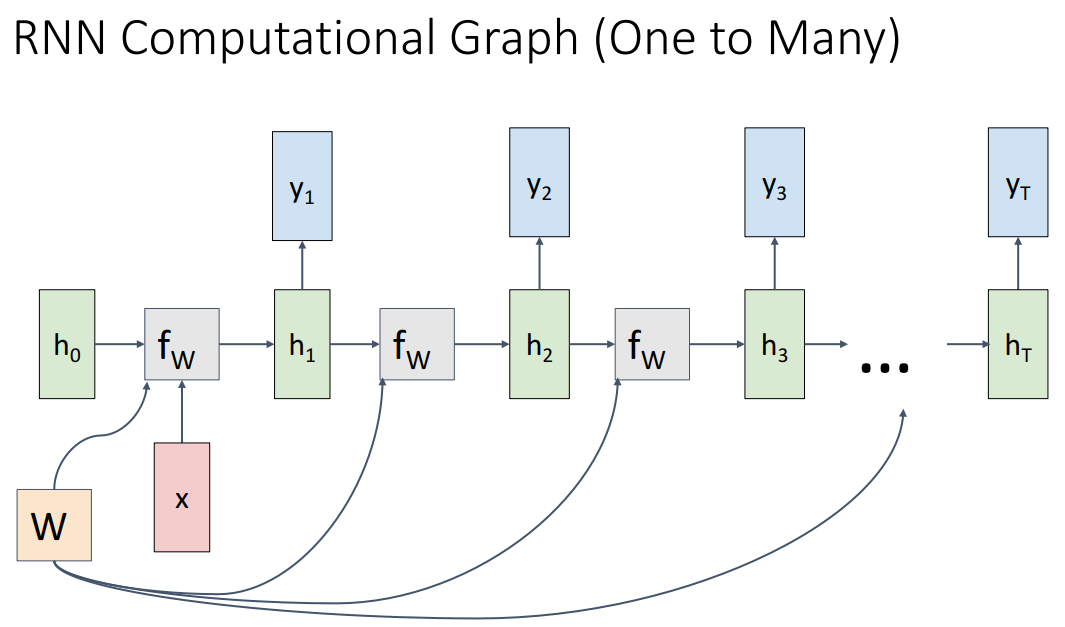
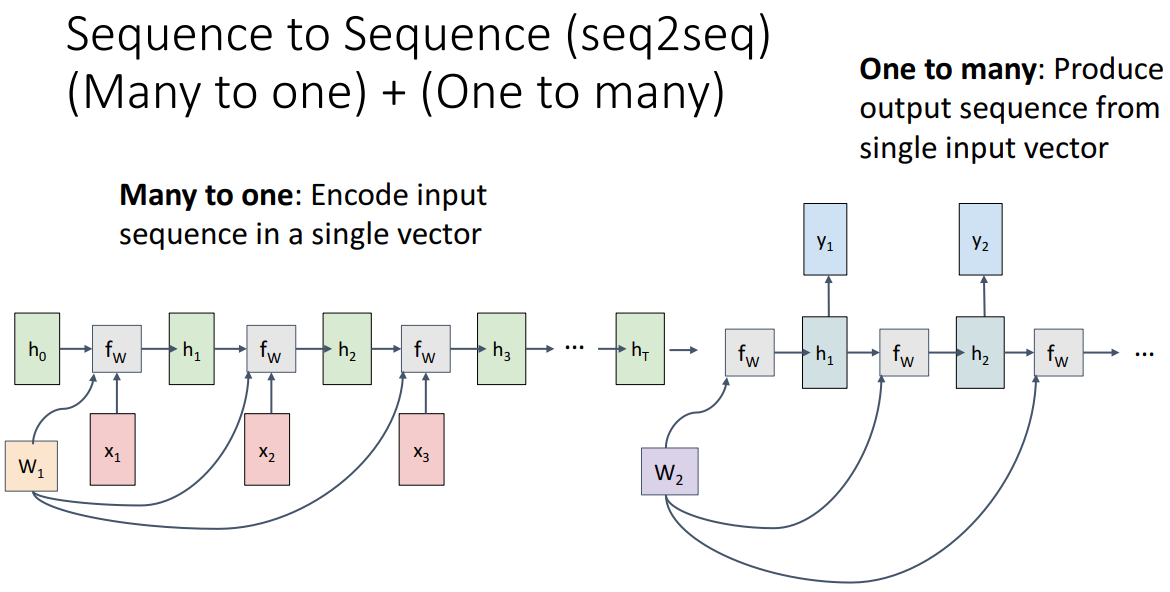
다양한 RNN의 형태에 따른 Computational Graph이고 여기에서 주의할 점은 모든 시간에서 주황색 박스 W가 동일한 값이라는 거다.
간단하게 설명해서 뒤에서 더 자세하게 할 수도 잇겟지만 many to many는 각 단계에서 loss를 계산하고 더해서 최종 손실이 결정된다. many to one은 마지막에만 단일 예측이 나타나고 one to many는 단일 이미지에 대한 설명이 문장으로 나타나는 image captioning에서 많이 나타나는 방식이다. seq2seq는 각 시퀀스 길이가 다를 수 있는 상황 (예를 들면 기계번역)에서 나타날 수 있다.
seq2seq에서 알아야 할 점은 many to one은 인코더역할, one to many는 디코더역할로써 수행이 되는데 각 w는 다른 가중치를 가지고 있다. 그리고 many to one에서 single output이 나오게 된다.
seq2seq는 디코더에서 <sos>벡터가 시작 벡터가 되고, 마지막에 <eos>벡터가 나오면 문장이 마무리 되었다는 뜻이다.


왼쪽부터 차례로 hell을 넣어서 o라는 값을 예측할 수 있게 만들어놓은 상황이다. 현재는 훈련과정이고, hello는 4가지의 문자로 이루어져서 4개의 벡터를 가지는 원핫벡터로 나타낼 수 있다. 그래서 hidden layer을 거치고 이에 가중치를 곱한 값이 output layer로 나오게 된다.
아 또 원핫벡터로 표현되다보니?? cross entropy loss가 사용된다고 한다 먼소리
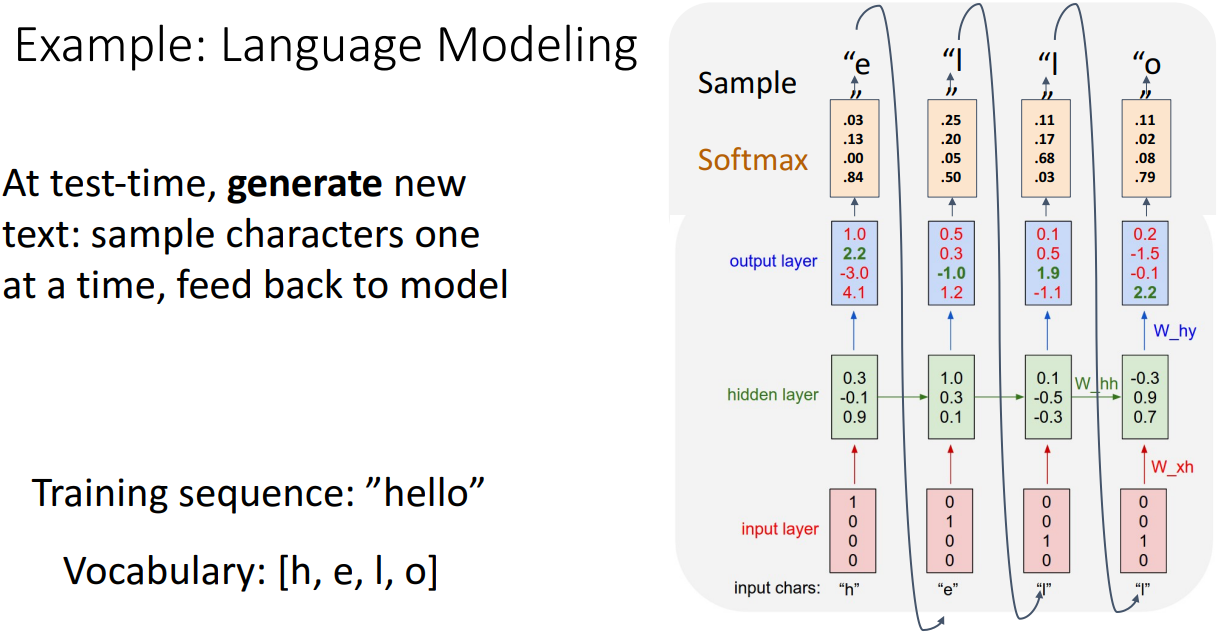
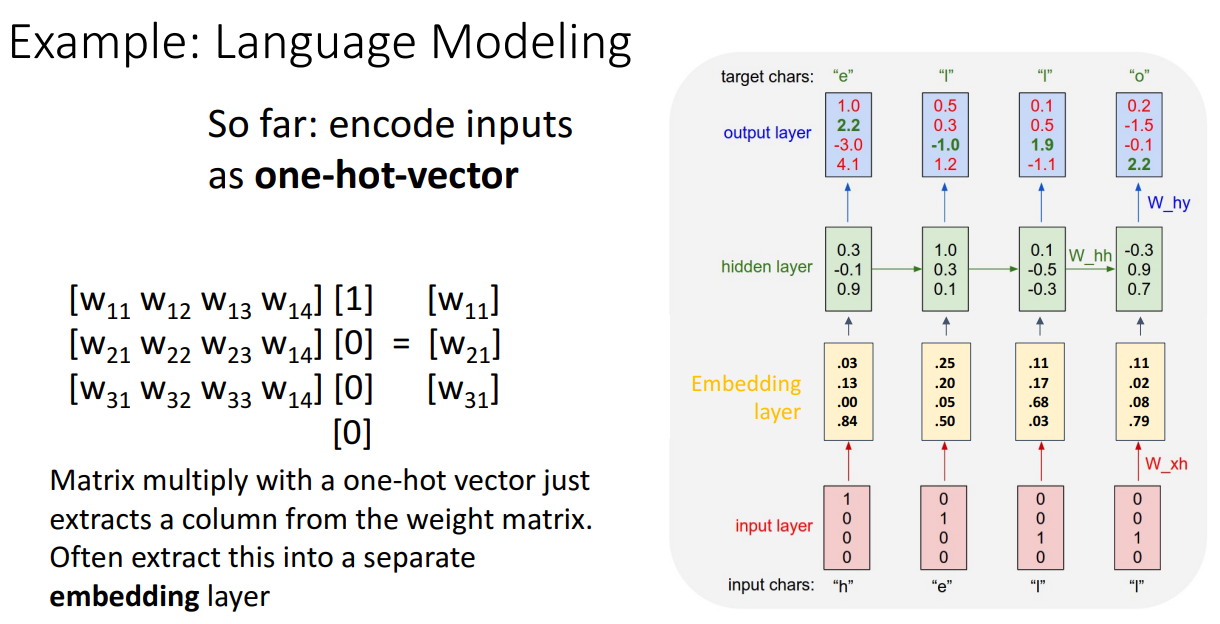
이번에는 위에서 학습한 모델을 바탕으로 hello를 예측해볼거에요! 지금은 test time! 그래서 input은 h달랑 하나만 주어지게 되면 모델에서 output에서 softmax를 거쳐서 다음에 나올 단어를 예측하고 이 단어가 다음 input으로 들어가게 된답니다!!
그리고 one-hot vector를 직접 matrix 곱셈하는 과정은 비효율적이기 때문에 embedding layer를 통해 해당 단어의 임베딩 벡터를 바로 가져오게 되었당
embedding layer란?
각 단어를 dense vector로 변환하는 층!
예를 들어 one-hot encoding은 10,000차원 벡터에서 하나의 요소만 1이고 나머지는 0이어서 메모리 낭비도 심하고 의미도 포함하지 못함 → 단어 간 유사도 같은 것을 표현할 방법이 없움
하지만 embedding을 사용한다면 단어의 의미도 표현할 수 있고, 더 저차원의 공간에서 효율적으로 정보를 추출할 수 있음
여기에서 사용한 이유는 해당 인덱스에 대한 임베딩 벡터를 반환하기만 하면 되어서 연산이 더 효율적으로 이루어지니 사용한 것 같다.
Teacher forcing

teacher forcing을 쓰는 이유는 t-1 번째에서 정확하지 않은 예측이 이루어졌다면 잘못된 정보를 input으로 받는 모델은 당연히 틀린 방향으로 추론할 것이다. 이렇게 되면 학습 초기에 학습 속도 저하가 많이 일어나서 나쁘다고 한다. 그래서 Ground Truth를 넣어주게 되면 초기 학습 속도를 빠르게 올릴 수 있다고 한다.
단점은 학습과 test단계에서의 차이가 존재하여 모델의 성능과 안정성을 떨어뜨릴 수 있다고 한다...
w가 고정되어있으면 같은 단어가 들어가면 항상 같은 값만 나오겠지? 그런데 이 때 train과정에서 틀린 답을 내면 안되니 우선 모델이 정확하고 잘 맞춘다! 라는 가정 하에 틀린 분포로 답이 나와도 정답을 넣어주는거다. 이걸 하는 이유는 학습 속도를 더 빠르게 하기 위해서.
그리고 test time에서는 teacher forcing을 사용하지 않는다. 정답값을 모르는데 또 w가 고정되있으니 같은 단어가 들어가면 같은 output들만 나올테니 이를 방지하기 위해 softmax에서 나온 결과값을 바탕으로 top-3같이 확률이 높은 몇 개의 결과값 중에서 랜덤으로 output을 sampling하는 식으로 진행이 된다고 한다.
여기에서 그런데 비효율적인 점은 원핫벡터와 가중치를 곱하면 어짜피 가중치의 한 열만 결과로 나오는데 뭐하러 벡터연산을 하냐!! 따라서~ 열 하나를 추출해주는 embedding layer을 추가를 한답니다. 아 말투 일관성있게 해야하는데
쨌든 여기는 논문을 오늘 읽어보도록 하삼

RNN의 문제점은 backprop을 하기에 무한으로 input이 들어오게 되면 매우 큰 메모리가 필요하다. 모든 순간에서의 loss값을 전부 더하기엔 에바이기 때문에.. 각 청크로 나눠서 forward, backward를 반복하게 된다. 두 번째 청크의 forward의 첫 번째 hidden layer을 계산하기 위해 필요한 h0은 이전 청크의 최종 h를 사용한다. w도 backward로 갱신된 것을 다음 청크에서 사용하게 된다.

굿 픽처...

이 부분은 조금 이따 쓰도록 하겠다...이게 뭔데
이제 두번째 예시는 image captioning인데 이는 one to many라고 볼 수 있겠다.

대충 이렇게 생겼는데 이미지 하나를 cnn을 거쳐서 특징벡터를 추출하고 난 후에 이를 rnn의 hidden layer을 만들 때 input으로 포함하게 된다.
근데..여기에서 쓰는 cnn모델이 pretrain된 모델을 가져오는데 마지막에 이미지 분류를 위해서 쓰엿던 fc-1000과 softmax를 잘라버린 모델을 사용한다.

이게 train time에서는 항상 이 cnn을 통한 특징벡터도 항상 추가가 되고, train단계에서는 이미지랑 실제 description이 주어진다고 한다!!
아항 그럼 이해 되지
그리고 이제 저 사진은 test단계인데 start토큰 들어오면 hidden state계산하고 나온 결과인 man을 다음 input으로 넣는 식으로 진행이 된다.
결국 t-1까지의 단어들이 입력으로 들어왔을 때 t번째 단어에 무엇이 올지를 예측하는 것을 rnn으로 그냥 구현한거다.
여기에서 생기는 문제가 멍미.. 바로 backprop시에 기울기 소실 or 폭발 문제! 항상 레이어가 깊게 쌓이면 생기는 문제인데 rnn도 역시 많은 연속적인 input이 들어오게 되면 같은 문제가 발생하게 된다. 그리고 RNN은 최근 몇개의 단어가 다음 단어를 예상하는데 큰 영향을 준다. 따라서 문맥을 훨씬 전에서 부터 봐야 하는데, RNN은 이 격차가 커질수록 예측을 하지 못하는 단점이 있다. 따라서 긴 시간동안의 정보를 기억하는 것도 가능하게 한 LSTM이 등장하게 되다.
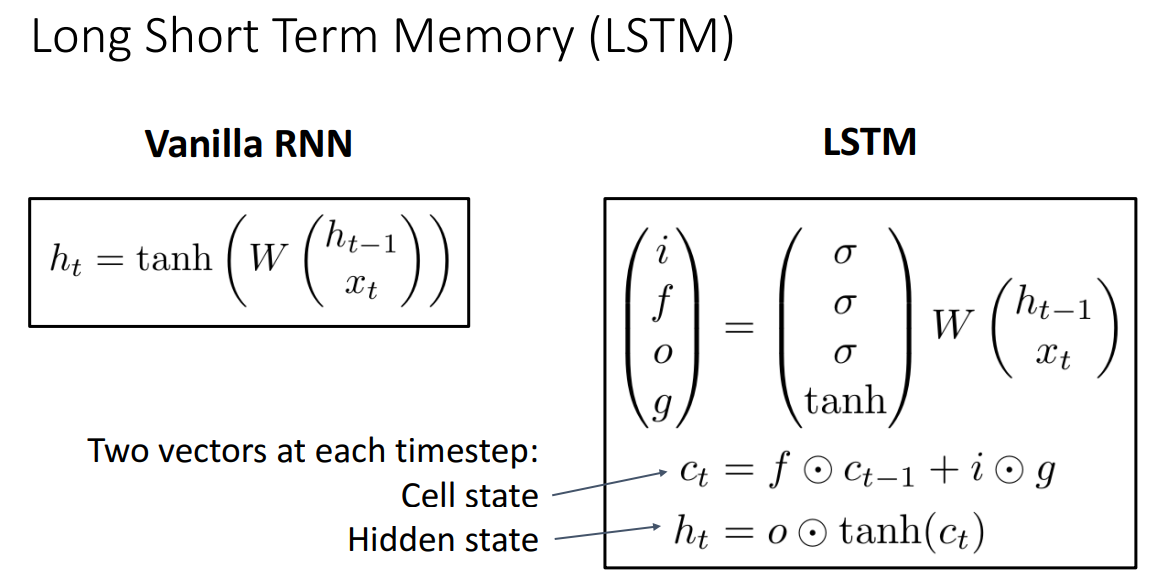
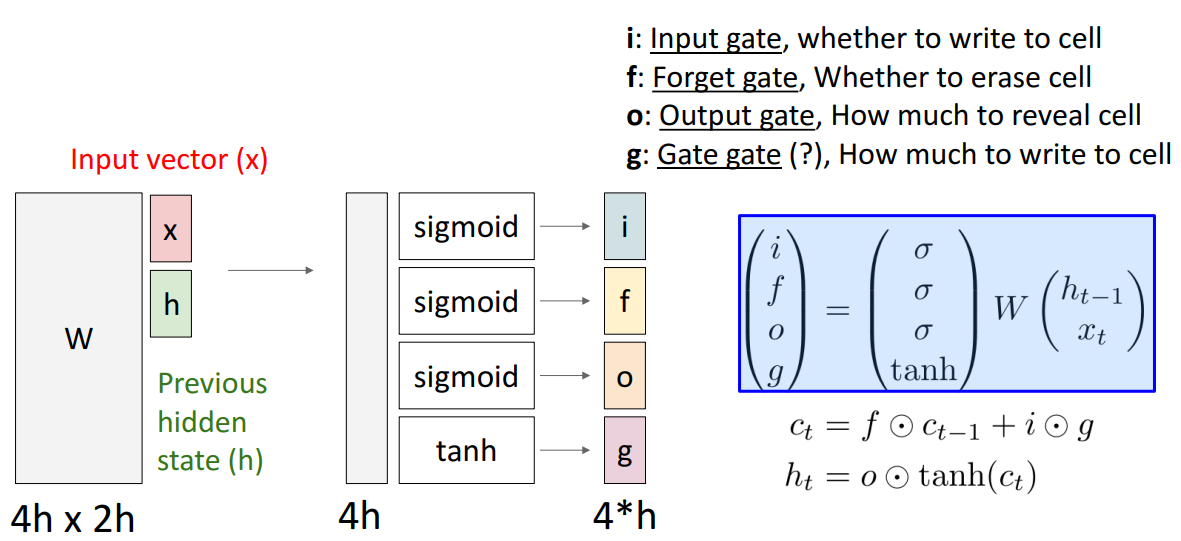
여기서 중요한 점은 state가 2개라는 .인듯 Cell state의 추가가 중요하다.
Cell state는 long-term dependency문제를 해결하였던 방식이다.
이는 이전 상태에서 현재 상태까지 유지되는 정보의 흐름을 나타내며, 이를 통해 오래된 정보를 기억하고 새로운 정보를 적절하게 갱신할 수 있다.
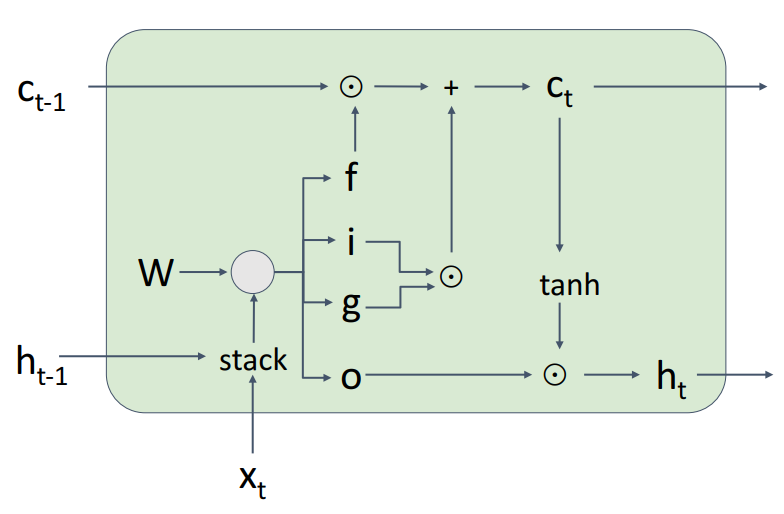
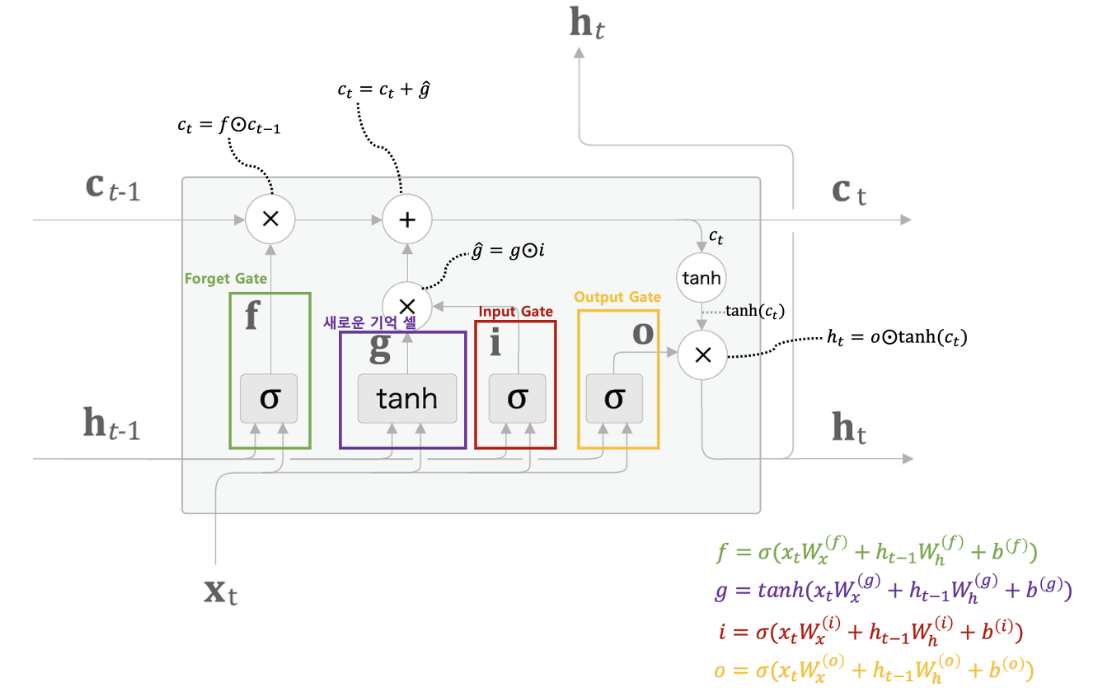
왼쪽이 피피티 오른쪽은 인터넷에서.. 오른쪽이 이해가 더 잘 가요
먼저 여기에 눈동자같은 동그라미는 아다마르곱이라는 것인데 동일한 형태의 두 행렬이 있을 때 각 원소별로 곱한 것이라고 한다. 똑같은 위치에 있는 애들을 곱해주면 되는 것!
자! 먼저 forget gate는 sigmoid func을 거친 값인데 이는 이전 hidden state값과 현재 input을 받아서 이전 cell state의 정보를 얼마만큼 보존할지를 결정하는 gate이다. 1이면 모두 보존하게 된다.
다음은 gate gate(?)이다. 이는 tanh함수를 사용하는데, 이는 흐르고 있는 기억셀 C에 어떤 새로운 기억 후보값들 vector을 output으로 내기 위함이다. 이는 다른 gate들이 정보를 얼마나 흐르게 하기 위함(정도)과는 다르게 정보값 그 자체에 의미를 더 부여하는 것 같아서 tanh를 쓴다고 이해했다.
다음은 input gate인데 이는 gate gate로 만들어진 새로운 정보를 얼마나 cell gate에 업데이트 시킬지를 결정하게 된다. 후에 덧셈을 하면서 Ct값을 더 다양한 정보를 가지게끔 한다.
마지막은 output gate이다. 이는 tanh의 각 원소가 다음 은닉상태벡터에 얼마나 중요한지를 정하는 것이다.
마지막으로 이 그림에서 생략된 선이 있는 것 같은데 1. Ct에서 tanh를 거친 값과 2. Ht-1과 Xt가 output gate를 지나 나오게 된 값을 곱해 Ht가 output으로도 나온다고 한다. 아 그냥 hidden state로도 output으로 나가니까 그런가보다?

이런 LSTM이 기울기 소실을 막을 수 있는 이유는 우선 역전파를 덧셈과 곱셈연산밖에 하지 않는다. 덧셈은 국소적인 미분 값을 그대로 같은 값으로 흘러보내서 기울기 변화가 일어나지 않기 때문에 소실이 일어나지 않는다. 상류의 기울기를 그대로 흘릴 뿐이다.
그리고 곱셈연산이 행렬곱 연산 역전파가 아니어서..? 라고 한다.. 아다마르 곱이어서 라고 하는데.. 흠냐링 원소별로 독립적으로 처리해서?...
RNN은 행렬곱셈과 non linear를 통해 역전파 해야하는 경로가 존재한ㄴ다..!
또 게이트값들이 매 시각마다 달라져서 곱셈의 역전파를 수행해도 매번 다른 값을 가지고 수행하기 때문에 곱셈의 효과가 누적되지 않아서 괜찮다. 그 이유는 모든 게이트 값들이 학습을 할 때마다 W값이 달라질 것이기 때문이다.