사실 알고는 있지만 블로그로 이해했기 때문에..
논문을 제대로 읽어보았습니다!!
파이팅.
0. Abstract
- 단순히 attention 메커니즘만으로 이루어진 모델로 RNN과 CNN을 성능으로 이길 수 있음
- 실험을 통해 알아낸 장점으로는 더 높은 품질, 병렬처리 가능 그리고 훈련 시간 단축이 있었음
1. Introduction
- 언어 모델이나 기계 번역 같은 문제에서 RNN, LSTM과 같이 sequence 모델링이나 번역 분야에서 SOTA였음
- Recurrent 모델은 입력과 출력의 위치에 따라서 연산을 수행하는데, 병렬 처리가 불가능하기 때문에 긴 time sequence에서 효율적이지 못함
- Attention 메커니즘은 굉장히 중요한 파트가 되었지만 여전히 RNN과 연결하여 사용함
→ 효율적인 병렬화가 불가능
⇒ RNN을 사용하지 않고 attention 메커니즘에만 의존하여 input, output의 전역적인 의존성을 모델링 할 수 있는 구조를 제안
2. Background
- 기존의 연구들에서도 sequential한 계산을 줄이기 위해서 연구를 진행했는데, 모두 CNN을 기본 모델로 사용하게 됨
- → 거리의 위치에 따라 계산량이 증가하는 단점 존재
⇒ Transformer에서는 multi-head attention으로 상수 시간의 계산 만으로 해결
- Self-Attention는 한 문장 안에서 다른 position에 있는 sequence들 간의 관계를 계산하기 위해 사용
- End-to-end memory networks는 sequence align recurrence 방식 대신 recurrence + attention 방식을 기반으로 동작하여 우수한 성능을 나타냈음
⇒ Transformer는 재귀 방식 없이 attention mechanism을 통해 의존성을 찾을 수 있다!
3. Model Architecture
기존의 경쟁력 있는 sequence model의 특징
- 기존의 encoder-decoder structure는 seq2seq형태로 z를 받아야 decoder가 step마다 output sequence를 생성할 수 있었음
- auto-regressive로 이전까지의 출력을 가져와서 새로 넣어줘야 다음 step을 예측하는 형태
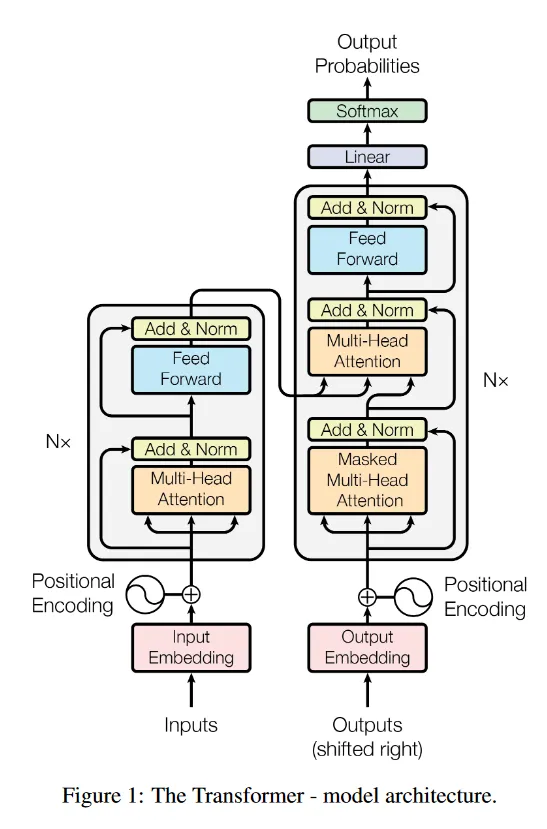
3.1. Encoder and Decoder Stacks
Encoder
- 6개의 identical layer를 쌓아서 만듦
- 각 layer는 2개의 sub layer로 구성됨
- multi-head self-attention mechanism
- position wise fully connected feed-forward
- sub layer 각각은 residual connection을 적용하고 layer normalization을 적용함
- residual conenction을 위해 모든 layer의 dimention은 512로 맞춤
Decoder
- encoder와 같은 6개의 layer
- encoder에서 sub layer뿐만 아니라 인코더의 output을 받는 multi-head attention도 존재
- residual connection, layer norm
- self-attention sub layer에서 다음에 나올 단어를 참조하지 못하게 mask를 씌움
3.2. Attention
- query와 key - value쌍을 output으로 mapping하는 function
- output은 값들의 weighted sum으로 계산
→ query와 해당 값에 대응하는 key 간의 유사도를 측정하는 함수를 통해 결정
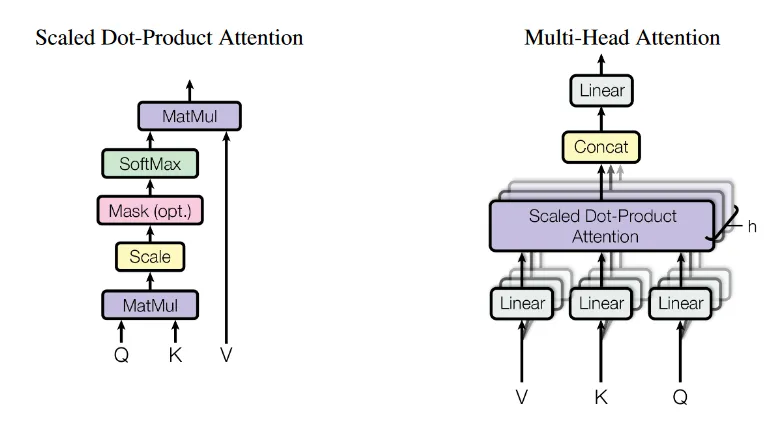
3.2.1. Scaled Dot-Product Attention
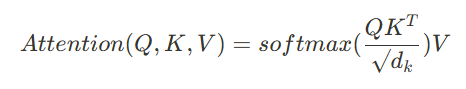
- dot product를 모든 query와 모든 key간에 진행한 후 key의 차원만큼 루트를 씌워주게 됨
- query와 key의 값이 커질수록 행렬곱 연산은 값이 더더욱 커지므로 softmax를 씌웠을 때 기울기 소실이 발생하므로 나눠줌
- value에 적용할 weight를 구하기 위해 softmax를 씌워줌
- query, key, value가 각각 한 matrix에 함축되어있어 동시에 계산
3.2.2. Multi-Head Attention
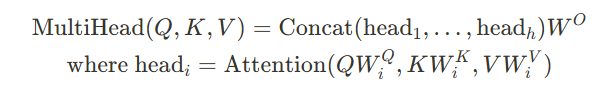
- 단일 d차원의 모델들을 사용하는 대신에 여러 개의 linear projection으로 projection시켜 병렬적으로 h번 계산
- 각 head에서 projection되면 최종 결과물은 concat시킴
- h개의 방면에서 다양한 정보들을 살펴보는 효과
- 단일 head를 쓰면 정보를 평균 내는 과정에서 정보 희석이 될 수 있음
- 최종적으로 cost는 single-head attention과 비슷
(Wo는 output의 차원을 모델의 output 차원으로 맞춰주려고)
3.2.3. Applications of Attention in our Model
multi-head attention의 사용 방법들
- encoder-decoder의 attention layer
- decoder에서 나온 query를 이용해 encoder에서 나온 key, value들을 모두 한 번에 볼 수 있게
- encoder의 self-attention
- key, query, value가 모두 같은 곳에서 나오게 됨
- 이전 layer의 출력을 참고하면서 self-attention
- 문장 전체의 문맥을 볼 수 있음
- decoder의 self-attention
- 음의 무한대로 마스킹을 사용해 후에 예측해야 할 단어는 보지 못하게 함
- auto-regressive의 속성은 유지
- 이 외는 encoder의 attention과 동일
- 음의 무한대로 마스킹을 사용해 후에 예측해야 할 단어는 보지 못하게 함
3.3. Position-wise Feed-Forward Networks
- attention의 sub-layer 다음에 FFN을 사용
- 각 단어 position마다 독립적으로 사용 → 다른 단어면 output이 다르게
- 같은 layer에서는 모든 위치에서 동일한 연산을 수행, 층이 다르면 다른 파라미터를 사용
- linear relu linear 순서
- 단순한 선형변환인 attention에 비선형성을 추가해 표현 학습을 도움
- 예시로 1d conv를 들 수가 있음!
attention과 비교한다면 이는 모든 단어가 서로 다른 단어를 참조하면서 다르게 연산 되나, ffn은 동일한 가중치를 사용하여 일관된 변환을 한다는 것
3.4. Embeddings and Softmax
- input token과 output token을 d차원으로 변형시키기 위해 임베딩을 사용
- 두 임베딩 레이어와 softmax직전의 linear transform에서 같은 가중치 사용
- 모델의 크기를 줄일 수 있음
3.5. Positional Encoding
- sequence 정보를 활용하기 위해 positional encodings 정보를 input에 더해서 사용
- 길이 k에 따라서 상대적인 위치에 따라 attention할 수 있게 함
- 싸인, 코싸인 함수 사용
- training에서 보지 못한 긴 문장에서도 효과적으로 작동할 것이라고 예상
4. Why Self-Attention

각 layer의 복잡도, 순차 연산의 최소 횟수, 다른 위치까지 정보 전달하는데 필요한 단계 수
Attention을 사용하는 이유!
- total computational complexity per layer
- 문장 길이 n이 차원 d보다 보통 작음 → attention이 보통 good
- 엄청 긴 sequence가 온다면? r의 이웃만 고려하도록 하는 restriced attention을 사용할 수 있음
- amount of computation that can be parallelized
- attention은 병렬 연산이 한 번에 이루어짐
- rnn은 순환 레이어로 step만큼의 연산이 이루어짐
- path length between long-range dependencies
- forward와 backward를 하는 거리가 짧을수록 멀리 있는 단어들 간의 관계를 보기 쉬움
- attention은 병렬로 한 번에 멀리 떨어진 단어도 보기 가능
- cnn은 필터만큼의 정보만 확인 가능
+attention이 어디로 향하는지 보아 해석 가능한 모델
5. Training
- WMT 2014 English-German 데이터셋 & WMT 2014 English-French 데이터셋 사용
- 각각 byte-pair, word piece encoding
- 배치는 비슷한 시퀀스 길이를 가진 문장 쌍으로 구성
- 각 배치는 25,000개의 문장 쌍이 존재
Residual Dropout
- 각 sub layer의 output에 dropout 적용(norm 적용 전에)
- positional encoding + encoding에도 dropout 적용
- 10%의 드롭아웃
Label Smoothing
- 특정 클래스에 대해 확신을 가지지 않도록 함
- 0.1 스무딩 적용
- 불확실성은 올라가나 정확도와 BLEU 점수는 올라감
6. Results
번역 task에서 낮은 훈련 비용으로도 SOTA보다 성능이 더 좋았다~
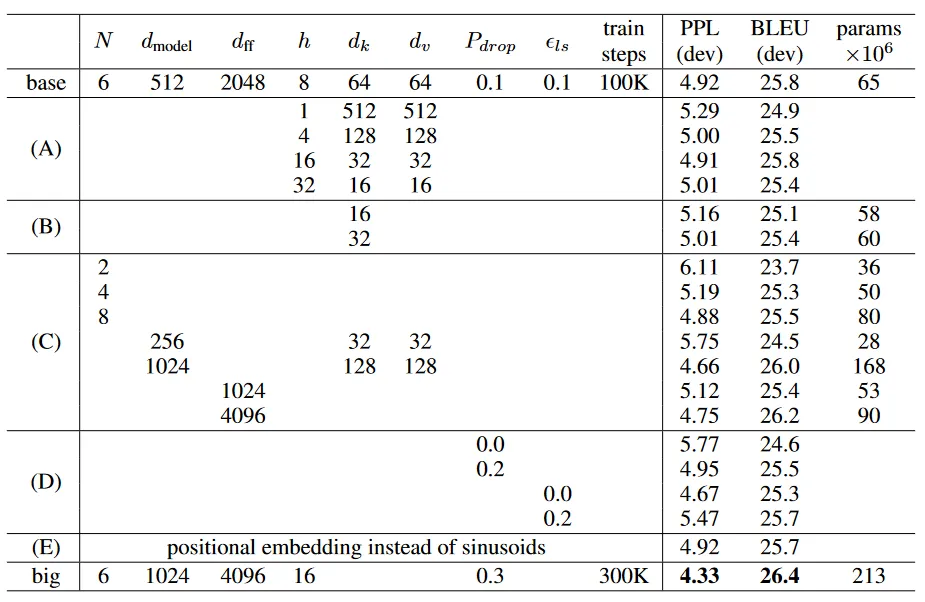
- multi-head attention이 성능이 좋은 것을 확인 → 너무 많이 나눠도 안 좋음
- key의 차원을 줄여보니 성능 저하 → query와 key의 관련성을 제대로 알지 못함
- 더 복잡한 query와 key의 관련을 나타내는 함수가 필요할 수 있음
- 모델이 커질수록 성능 향상, dropout의 성능 관찰
- positional encoding을 할 때에 학습된 임베딩을 사용해도 성능이 유사함
| 작성자 | 배세은 |
| 소 감 | attention에 대해서 다시 복습하게 되어서 좋은 시간이었다. 앞으로 멀티모달 인공지능에서도 attention을 사용한다고 하는데 오늘 복습한 것을 바탕으로 열심히 공부해보아야겠다. |
| 일 시 | 2025. 3. 31. (월) 18:00 ~ 21:00 |
| 장 소 | 미래관 429호 자율주행스튜디오 |
| 참가자 명단 | 신수민, 임혜진, 배세은, 김윤희 (총 4명) |
| 사 진 |  |
'세은' 카테고리의 다른 글
| [호붕싸 모각코 8차] Visualizing and Understanding (1) | 2025.04.11 |
|---|---|
| [호붕싸 모각코 7차] 논문 리뷰 - CLLMate: A Multimodal LLM for Weather and Climate EventsForecasting (0) | 2025.04.04 |
| [호붕싸 모각코 5차] Image Captioning - Evaluation (0) | 2025.03.24 |
| [호붕싸 모각코 4주차] 컴퓨터 네트워크 - 인터넷의 구조와 네트워크 접근 방식 (0) | 2025.03.22 |
| [호붕싸 모각코 3주차] Semi-Supervised Learning (0) | 2025.03.17 |