Visualizing을 하는 이유
- cnn모델이 내부에서 어떻게 작동하는지 신경망 내부의 가중치를? 직접 확인
- visualizing하고 understanding하는 기술이 deep dream이나 style transfer같은 기술에도 사용될 수 있음
cnn을 만들고 큰 데이터셋에서 학습을 하면 .. 이제 각 신경망이 찾는 feature들이 무엇인가!
그리고 어떤 feature를 찾아낼 수 있는지 파악하게 된다면?
→ 왜 모델이 동작하지 않는지.. 등등에 대한 직관을 얻을 수 있겠지?
따라서 직관을 얻기 위함이 목표!
template matching은 그.. 비슷한 이미지끼리 내적하면 값이 커지는 것을 이용하여서 class를 구분하는 것이었는데 여기에서도 똑같이 사용!!
이 모델들에서 첫 번째 layer를 그냥 visualizing시킴.. rgb channel로!
→ 레이어가 찾는 feature이 무엇인지 알 수 있음 → imagenet으로 학습시킨 모델들!!
- 보통 첫 번째 layer가 찾는 feature는 이미지의 edge나 모서리 부분이나 색이 바뀌는 부분
- 모델 아키텍처가 달라도 대부분 첫 번째 layer는 똑같음
이 같은 기술을 higher layer에 적용하면?
- 이제 입력 채널의 수가 rgb로 국한되지 않고 그냥 이전 필터의 개수만큼으로 생성되니 feature map을 시각화 하기에는 어려움이전 layer에서 edge를 찾은 것에서 더 자세한 패턴을 찾을 것
- 근데!! 정확한 직관을 얻긴 어려워
→ gray scale로 spatial structure을 찾는 것을 볼 수 있음
따라서.. fc layer에서 어떤 일이 일어나는 지를 확인한다~
ex) 알렉스넷에서 4096 차원 → 10차원으로 줄였을 때 이걸 visualizing을 해보겠다??
각 class에 해당하는 이미지들의 vector들을 저장해놓고 시각화 해보기
어떤 방식으로?
Last Layer:
Nearest Neighbors
nearest neighbor를 적용해서! feature space에서 적용을 해보면 pixel space에서 했을 때는 이상한 결과가 많이 나왔었는데 색만 보는게 아니라 alexnet에서 각 물체에 대한 정보를 인코딩해서 4096 feature로 만들기 때문에 정확한 결과가 나올 수 있게 함
질문. feature끼리 가까운 정도를 유클리디안 거리로 알아낸다고 했는데.. feature space의 차원과 이 거리 계산 방법? 4096 feature마다 elementwise로 빼서 제곱해서 거리 계산하나? ⇒ 맞는 듯 해결 완
Dimensinality Reduction
차원을 4096 → 2로 줄여서 시각화
고차원 feature를 유지하면서 저차원으로 투영!
- pca데이터의 공분산행렬을 구해서 이 공분산행렬의 고유값과 고유벡터를 찾고 고유값의 크기 순서대로 고유벡터를 정렬하여 주성분을 선택함
- t-SNE(t-distributed Stochastic Neighbor Embedding)방법을 살펴보자면 고차원 공간에서의 점들의 유사성과 저차원 공간에서의 점들의 유사성을 계산을 하는데 이 때 저차원 공간에 점들을 랜덤으로 초기화를 시킴 비선형 구조를 유지하면서 차원 축소
- 고차원 공간과 저차원 공간 간의 유사성을 선형 관계로 나타내지 않고, 비선형적인 확률 분포로 변환
- 고차원 공간에서의 데이터 포인트의 similarity를 구하고 저차원 공간에서의 데이터 포인트간의 similarity를 구해서 이 확률분포? 간의 차이를 줄이기 위해 kl divergence로 두 확률분포간의 차이를 구해서 이를 최소화 하는 방식으로 cost function을 미분하고 데이터 포인트별로 gradient를 구해서 저차원상의 데이터를 변환하는 식으로 진행됨
- *차원을 축소하는 방식이 Auto-Encoder, pca, auto encoder이 있음 여기에서 auto-encoder는 모델 학습을 시켜야 함, 이거랑 pca는 유의미한 의미를 남길 수 있는 feature로 차원을 축소시키기 위함, t-sne는 그냥 시각화가 목적이기 때문에 가까운 것들은 가깝고 먼 것들은 멀게 시각화 하는 것이 목적이다! 따라서 이렇게 나온 feature들을 가지고 뭘 할 수는 없음! → 데이터의 군집 구조를 시각화하는데 사용 됨
- 우선 목적은 시각화를 하기 위해 만든 기법임
Visualizing Activations
conv에서 activate되는 부분을 시각화 시킴 → filter가 이미지의 어떤 특징에 반응하는지 알 수 있게
하나 확대하니까 얼굴 감지하는 듯한 활성화 보임
→ 사람의 얼굴에 반응하는 법을 배움
20분 즈음 좀 더! 이미지 밝기에 영향을 준다는 부분…?
0 ~ 무한대에서(activation값?) 픽셀인 0 ~ 255 scale로 낮춰야 함 그래서…
근데 이게 사람 얼굴을 filter에서 확인을 한게.. receptive field 덕분에 이제 전체적인 그림을 볼 수 있게 되어서 그런거겠지??f
Maximally Activating Patches
전체 훈련 세트를 가져온다…?
특정 레이어의 특정 필터를 지정해놓고! 들어오는 데이터들에 대해서 기록을 함(레이어 정하고 여러 filter들에 대해 진행하나보다)
이 때 filter이 돌아가면서 feature를 추출하니 필터 크기만큼 유한한 사이즈!
높은 activating을 하는 테스트셋 이미지 패치를 찾아~~ & 기록
→ 선택한 filter가 무엇을 찾고 있는지 어느 정도 알 수 있음
더 깊은 layer 시각화 할 수록 receptive field 넓어져서 더 넓은 패치 부분을 볼 수 있음
Which pixels matter?
- 마스크된 이미지 넣어서 분류 잘 하는지 파악하기: 마스크를 씌웠을 때 코끼리의 예측값이 낮아지는 위치의 mask가 있을건데 그건 heatmap이 높게 나오는 식으로 → 그럼 이걸 픽셀별로 다 돌아가면서sliding window 마냥 하는거겠지 좀 더 알아보기여기에서는 무슨 feature가 활성화되는지에 중점 X물만 보고 보트로 판단하는가 등의 cheating을 하고있는지를 확인할 수 있음
- → 이미지의 어떤 부분이 신경망에서 중요한가를 중점으로!
- 빨간색이 예측 점수!!!! 더 낮으면 그 부분이 더 중요하다는 뜻!!!
- heat map!
- backprop으로 알아보기softmax를 거치지 않은 값으로 이미지의 확률을 최대화 하는 방향으로 gradient ascent를 진행하게 됨많이 변경을 해야하는 pixel이 dog와 관련된 pixel일 것이다..
- 근데 실제로 이 예시들처럼 잘 되지는 않는다고 함
- dog라는 class정답으로 backprop을 하는데 이때의 기울기가 각 픽셀이 얼마나 영향을 주는지?? 를 알 수 있음
- 개 사진을 pre-train된 모델에 넣고 softmax로 output을 뽑아내고 실제 class랑 비교를 하면서 loss를 구한 후 noise image에 대해 backprop으로 이미지를 update함 → conv weight는 업데이트 하지 않음
Saliency Maps: Segmentation without Supervision
segmentation을 할 수 있다고..? 아 classification task로 학습한 모델을 gradient를 사용해서 활성화되는 물체의 부분을 보면 그 class 물체가 있는 곳을 알 수 있을 테니 segmentation task를 할 수 있게 한다? but 이것도 잘 안 됨
GrabCut 알고리즘 + saliency map으로 객체 분할하기
파랑색은 전경색, 빨강은 배경색
사용자가 이미지에서 대략적으로 물체가 있을만한 공간을 사각형으로 선택을 하면 사각형을 바탕으로 배경과 전경을 학습하고, 이미지 픽셀들을 노드로 보고 유사한 색상을 가진 픽셀들은 더 강한 연결을 가지는 식으로 물체를 구별하게 됨
→ 업데이트를 반복적으로 해서 최적화한다 saliency map으로 대략 전경을 구별할 수 있겠다!
Intermediate Features via (guided) backprop
backprop으로 활성화되는 곳을 찾는걸 pixel이 아니라 feature로!
특정 layer의 특정 filter를 정해서 이번엔 인풋 이미지에서 class정답이 아니라 해당 filter가 입력 이미지에 미치는 영향을 끼치는 부분을 알아보는 것임
네트워크 중간 뉴런이 입력 이미지의 어떤 부분에 영향을 끼쳤는지!
⇒ 입력 이미지에서 중간 filter가 보는 특징이 무엇인지를 확인할 수 있음
이때 뉴런이 cnn filter이겠지?
이 때 guided backprop을 사용하면 더 clean한 결과를 확인할 수 있음
patch 내부에서도 어떤 픽셀이 크게 영향을 줬는지를 알 수 있음!!!!
deconvnet이 머야
⇒ conv를 반대로 수행해서 feature map을 알고 있으면 역으로 input image 중에서 담당하는 부분을 시각적으로 알 수 있을 것임
근데… 여기에서 스위치 정보… 이거 말하려면 하고..
backprop 관련해서 test image에서 활성화 되는 부분을 알아보았다면 지금은 반대로 노드를 최대로 활성화시키는 정석 이미지를 만들어보자!
⇒ Gradient Ascent
Gradient Ascent
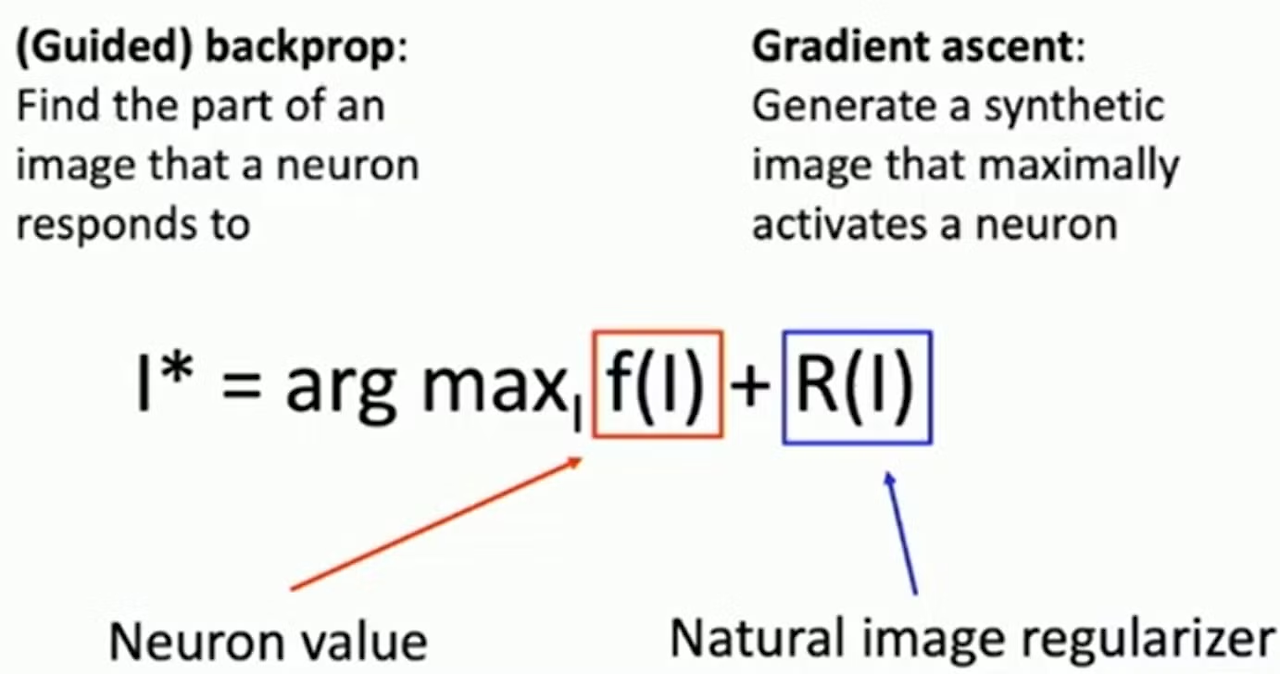
I*는 neuron의 활성화가 최대가 되게 하는 이미지, 이를 찾는 것이 목적
보통 이러한 식을 모델을 최적화 하는데 사용했지만 우리는 이를 최대화 하는 이미지를 찾는 것이 목적!
- f(I)는 이미지가 뉴런의 값을 얼마나 활성화 시키는지
- R(I)는 이미지를 자연스럽게 만들어주는 역할
초기에 원본 이미지를 0이나 무작위로 초기화 → 모델에 넣고 원하는 뉴런의 값을 추출하기 위해 backprop을 진행, 많은 영향을 주는 픽셀을 찾기 위해서.
Adversarial 어쩌고랑 똑같다?? 더 알아보기
우선 이미지넷의 카테고리 중 하나에 대한 클래스 점수를 최대화 하고 L2 reg도 낮은 이미지를 찾는 것이 중요
이미지 학습을 진행할 수록 원하는 class로 분류하도록 바뀌겠지?
이렇게 나온 이미지를 통해 우리가 특정 class를 구별하는 특징을 알아낼 수 있음
깊은 layer에서는 예를 들어 사람의 얼굴을 인식하는데 이때 여러 각도에서의 특징을 종합해야하니까 visualizing하기에 힘든 특성이 있음 → 복잡한 패턴을 이해하는 것을 보여주기 힘듦?
더 나은 regularization 방법
- gaussian blur image→ gaussian blur처리로 이런 성분 억제
- gradient ascent로 이미지를 생성하면 고주파 성분을 가지는 경우가 많음
- 작은 norm
- 이미지의 모든 픽셀 값이 0이 아닌 상태로 남아있으면 불필요한 부분 제거를 위해 제거하는게 좋음
- 작은 gradient 를 가진 것 0으로⇒ 기여도가 낮은 픽셀 클리핑
- 활성화가 작은 픽셀 찾아내 클리핑
class 뿐만 아니라 특정 neuron을 활성화시키는 이미지도 만들 수가 있음!!
이미지를 더 사실적으로 만드는 방법도 있다~ → 이거 알아봐야 할 듯
multi-faceted visualization
잘 시각화가 안되는 이유가 여러 측면들을 한 번에 표현하려고 해서 그럼
⇒ 특정 측면의 평균 이미지로 최적화를 하면 이미지를 더 잘 재구성 할 수 있겠다~
그런데!!! 이미지를 더 사실적으로 만들 수록 오히려 일반적인 이미지에서 멀어질 수도 있다~ 간단한 reg term이 오히려 일반적인 특징을 말해줄 수 있으니까!!
Adversarial Examples
혹시 reg term이 없으면 어떻게 될까?? → 근데 이 노이즈 때문에… reg term을 추가를 시킨거야…? 그건 아니고 그냥 저런 현상을 덜 일어나게 해주려고
한 class의 이미지에서 시작을 해서 정답 class를 다르게 준 후 gradient acsent로 다른 class로 분류하게 학습을 하도록 함!
픽셀을 아주 조금 변경시켰기 때문에 육안으로는 차이가 없으나 다른 class로 분류가 됨…
Feature Inversion
gradient ascent와 image gradient를 사용한 네트워크의 특징 추출 방식!
특정 이미지를 모델에 넣고 특정 layer에서 해당 이미지의 feature vector를 뽑아낸 다음 이 특징을 사용한 다른 그림을 생성하는 것! 맞겠지…?
이미지 만드는게 gradient descent겠지??
loss term은 생성한 이미지와 기존 이미지의 feature간 차이!! 최대한 특징은 같아야 함!!
상하좌우 픽셀간 차이를 더하면서 이미지를 더 매끄럽게 해줌
feature vector를 기반으로 계속 유사성을 비교해가며 생성해 나감
이거 하는 의미가… 여러 layer에서 feature이 버려지거나.. 무엇을 인식하거나.. 이걸 시각화 시킬 수가 있나??
reconstructing from different layers
→ 각 층에서 input에 대해 feature뽑고 그 feature특징을 갖고 있는 새로운 이미지를 reconstruction
layer가 깊어질 수록 low level의 정보가 손실됨을 볼 수 있음
→ low level의 feature은 초기 층에서 손실되니까?? 겠지?? ㅇㅇ
깊은 layer일수록 이미지 전체적인 공간 구조는 보존하지만 정확한 형태는 보존하지 못 함, 다양한 레이어에서 어떤 정보가 버려지고 유지되는지 알 수 있음
DeepDream
feature inversion을 재미로 바꾼 것
기존 이미지에서 존재하는 모든 특징을 증폭시키기!
maximize는 이미지를 완전히 변형시켜 특정 뉴런이 가장 크게 반응하는 이미지를 생성
amplify는 이미 존재하는 이미지에 특징을 더 두드러지게 만들어 이미지가 마치 꿈속의 장난처럼 보이게 함
모델 일부 layer에서 gradient를 뽑고 actiation값을 그대로 설정??하고?? 모르겠어 → 이게 무슨말이야
backprop을 통해 이미지 업데이트를 진행! → input image를 update 한다는 말인가?
L2 norm을 최대화 하는 것과 동일 → 그.. 위에서 최대한 생생한 사진 뽑아내는거랑 똑같은 건가
활성화 값을 제곱한 값을 gradient로 사용하면서 특징을 증폭시킴
양수나 음수나 제곱하면서 절대적인 영향력이 그냥 커지게 하는것
코드
이미지를 무작위로 이동 ⇒ 작은 변화에 대해서도 다양한 반응을 할 수 있게
forward와 backward를 통해 gradient 계산
l1 norm에서 gradient의 크기 조정을 함
jitter은 이미지를 다시 위치로 되돌림
clip은 이미지의 품질 유지되도록!
특정 layer에서 잡는 특징을 증폭시킬 수 있음
근데 깊은 layer로 하게 된다면 점점 본질에서 벗어나는 물체들이 등장함 →왜? 깊은 네트워크가 imagenet의 전체적인 특징을 학습한 것이라고 볼 수 있음
이게 꿈꾸는 것과 같다고 해서 deep dream
50쪽은 멀티 스케일 프로세싱으로 활성화
⇒ 이미지를 저해상도로 변환하면 큰 구조적 패턴이 강조됨 고해상도는 세밀한 디테일과 패턴
먼저 작은 크기의 이미지에서 deepdream ⇒ 해상도가 낮아서 텍스처나 패턴을 더 잘 볼 수 있음
점점 큰 크기의 이미지 ⇒ 더 큰 패턴이나 구조 강조하기
51쪽은 imagenet이 아닌 장소에 대한 데이터셋에 대해 학습한 결과 → 아예 다른 output이 나옴
Texture Synthesis
NN을 통해서 작은 texture 정보에 대한 이미지를 넓게 만들 수 있음 근데 conv를 안쓰고도 이런 걸 할 수 있다~~
⇒ NN하는 방법은 위에서 아래로 왼쪽에서 오른쪽으로 픽셀을 하나씩 생성하는데 현재 출력 이미지에서 특정 위치에 있는 픽셀의 주변 패치를 정의하고 예제 텍스처(인풋 패치에서 생성됨)에서 가장 유사한 패치를 찾아 그 패치의 중심에 있는 픽셀 값을 현재 출력 픽셀에 할당하는 방식
Gram Matrix
gradient ascent를 픽셀들에 적용하는 것 → texture 합성!!을 딥러닝으로!
feature inversion과 비슷함 → 원본 이미지를 가지고 특징을 가진 새로운 이미지 생성
이를!! texture 생성에 사용하는 기법~ feature를 더 증폭시켜 줌
이 때 texture이 뭐냐?? spatial structure는 따르지 않아도 되고 local의 texture structure만 따르면 댐!!
패턴, 질감, 색상, 대비 등 특정 패턴이 반복되는 것???
- 원하는 layer까지 이미지를 모델에 돌려서 chw만큼의 output을 추출함
- 2개의 채널로의 벡터를 2개 가져와서 outer product를 계산
→ 이 과정을 가능한 한 모든 쌍의 벡터에 대해서 진행, 평균 구함
이렇게 구한 gram matrix는 texture를 설명해준다
아 외적하는게 unnormalized 공분산을 만드는거였나??
이는 spatial structure는 모두 버려지게 됨 → hw로의 정보가 살아있어야 spatial structure가 살아있다고 생각해요
이 CxC matrix에 담긴 의미가 무엇인가?
spatial structure를 버리고 동시에 활성화가 되는 채널이 있다?? 이런 특징을 찾는 것!!
이걸로 gradient descent 방식으로 나아감
→ 두 채널 간의 내적이 클 수록 두 채널은 비슷한 패턴을 감지하거나 동일한 특징을 캡처하는 경향이 있다는 것을 의미
: 스타일을 정의하는데 중요한 요소가 될 수 있음
텍스처가 특정 위치에 국한되지 않고 채널 전체에 걸쳐 일관된 스타일을 나타내는 방식!!!
채널간의 전체적인 상관관계가 중요하다~!!!
텍스처 정보는 이미지에서 다양한 패턴이 어떻게 상호작용 하는지를 보여주는데 채널 간의 상관관계가 높으면 더 중요한 특징이다! 라고 해서 더 두드러지는 texture설명자로써 나타남??
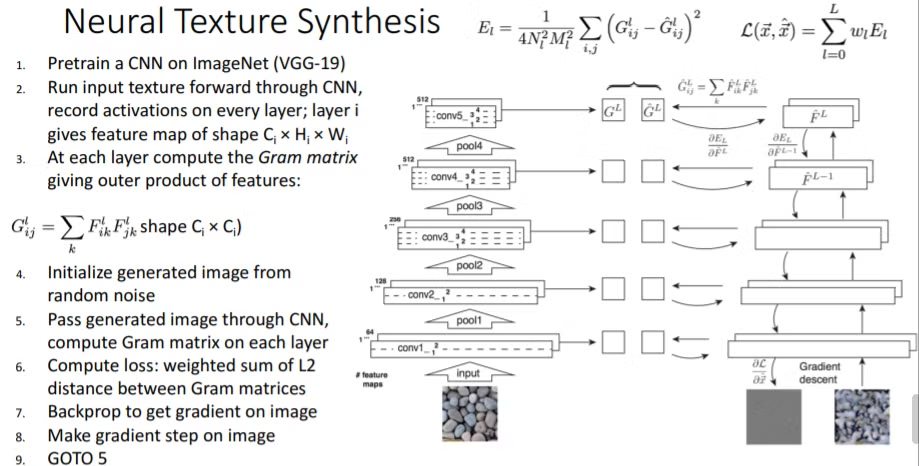
수식 설명
위에 E는 두 이미지의 gram matrix가 유사하게 하는 것
나누는 건 feature map의 c와 h*w임, 4는 스케일링 상수
L은 여러 레이어에서 나온 loss 가중합 하는 것
F가 뜻하는게 그냥 feature 값
대충 설명하자면 texture가 담긴 이미지를 pretrain된 vgg에 넣고 각 layer마다 gram matrix를 계산하고 똑같은?? 모델??로 noise를 인풋으로 집어 넣고 이것도 layer마다 gram matrix를 계산하여 각 layer마다 나오는 gram matrix의 loss를 유클리디안 거리로 weighted sum으로 계산을 함 그리고 backprop을 통해 얼마나 바꿔야 하는지 픽셀별로 gradient를 계산을 하고 gradient descent방식으로 노이즈를 학습시켜나감
단순히 낮은 층의 layer만 사용하면 texture의 구조가 거의 없고 noise에 가까운 형태가 됨
그런데 더 높은 구조까지 포함시키면 텍스처가 원본 이미지와 유사해지고 큼직큼직한 texture를 더 잘 잡아내는 것을 알 수 있음
Neural Texture Synthesis: Texture = Artwork
low layer에서는 색상정보와 같은 정보를 캐치하고 higher layer은 아무래도 더 receptive field가 넓으니까?? 더 큰 feature들을 잡아냄
higher layer에서는 texture정보는 input image와 같으나 spatial structure는 전혀 다른 새로운 이미지를 생성하는 것을 볼 수 있음
⇒ texture도 깊어질수록 더 큰 texture를 잡아냄
spatial 정보 vs local 정보
spatial 정보는 이미지의 전반적인 구조와 물체의 위치!
local 정보는 특정 작은 영역 안에 있는 디테일한 특성! ex) 텍스처
Neural Style Transfer: Feature + Gram Reconstruction
위에서 본 Texture synthesis와 Feature reconstruction을 합치는 것!
- Texture synthesis
- 깊은 층으로 갈 수록 spatial 정보는 파괴되고 texture와 색상 정보만 남게 됨
- Feature reconstruction
- 깊은 층으로 갈 수록 입력 이미지의 전체적인 spatial 정보는 유지하지만 텍스처와 색상정보를 파괴
이 둘을 합쳐보자! 가 아이디어다.
전체적인 구조는 유지하고 이에 뽑아온 texture를 적용하면 새로운 스타일의 이미지가 만들어 질 것! ⇒ 천재
우선 gradient descent로 노이즈에서 이미지를 만들어내는데 content image의 feature과 일치하고 gram matrix와 일치하게 만듦
content loss는 그냥 feature map끼리 비교
이 때 content와 style loss간에 원하는 방향으로 절충을 할 수 있음
style image도 resizing하면서 조금 특징을 다르게 만드는 쪽으로 만들 수 있음
크게 하면 섬세한 texture가 적용되고 작게 하면 더 큰 feature 를 texture로써 적용될 수 있음 이거는 별이 texture로 보여서겠지?
→ 여기 좀 더 자세하게 이게 맞나???
Multiple style Images
여러가지 style image를 gram matrix를 weighted combination해서 여러 스타일이 들어간 이미지도 만들 수 있음
와.. 갈 데까지 가서 style transfer + deep dream까지 할 수 있음
근데!! 단점이 이미지 생성을 위해 많은 backprop으로 여러여러 step을 밟고 많은 gradient ascent를 진행해야 함
그럼 이를 해결하는 걸 찾아야겠다
⇒ 존슨씨가 만드신 새로운 model
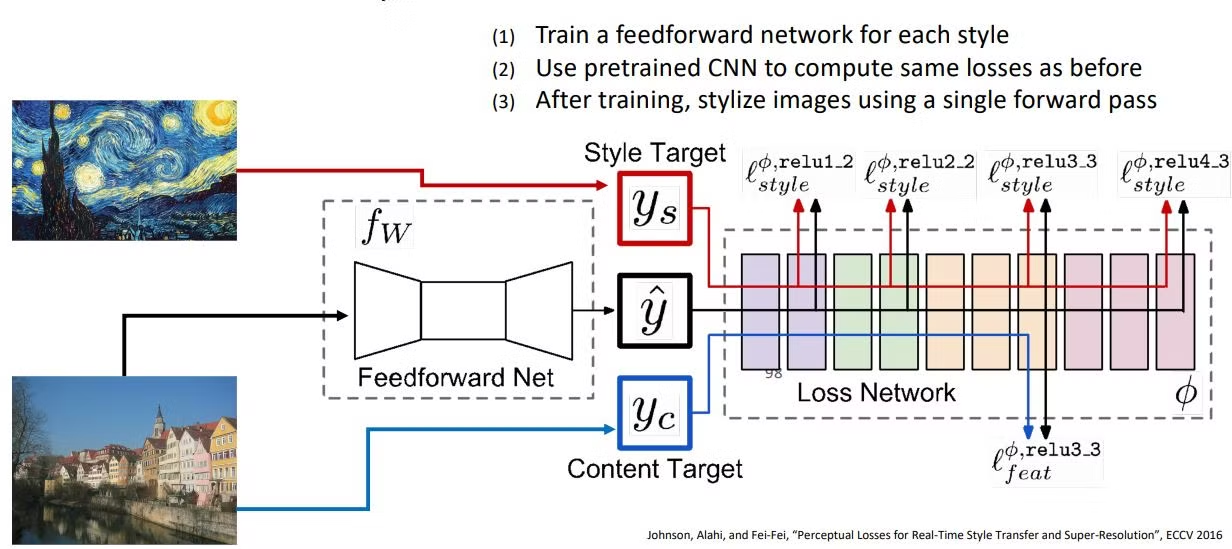
위 논문에서는 기존에
여기에서 feedforward net이 뭐냐!!!!!!!
다운샘플링, 업샘플링을 통해 출력 이미지의 각 픽셀
입력 이미지가 주어진 경우 출력 이미지에 바로 style이 부여된 output을 single forward pass로 만들어낼 수 있음
input은 content image이고 output은 스타일이 바뀐 이미지!
style마다 feedforward network를 먼저 학습을 시켜놓고 content image만 나중에 넣어서 원하는 스타일로 변하게 만듦
전에는 뭐.. backward pass할 것도 개많았는데 얘가 해결했나보다
→ 이제 realtime도 가능함!!
Instance Norm
이는 style transfer를 하기 위해 개발되었음
각 이미지의 channel들을 각각 normalize함 ⇒ 이미지의 모든 feature를 한 번에 norm시키는 batchnorm은 이미지 고유의 정보를 많이 손실 시켜버림
이미지의 밝기나 명암대비 같은 요소들이 이미지 스타일 변환 과정에서 영향을 많이 끼치지 않도록 함
batchnorm을 써버리면 이미지 간 명암의 차이가 모두 다를텐데 이를 한꺼번에 정규화 시키는 것보다 instance norm으로 인스턴스 별로 해야 명암같은 것이 더 잘 정규화 될 수 있음, texture나 패턴을 더 잘 유지할 수 있음!!!
채널별로 하는 이유도 색상정보와 같은 채널의 데이터 분포가 다 다르기 때문에 특성을 유지하기 위해서!
One Network, Many Styles
위에서 봤을 때는 한 모델마다 한 개의 style만 가질 수 있었다
근데 비용적으로 너무 비싸 ⇒ 한 개의 모델로 여러 style을 사용할 수 있게!
conditional instance normalization
다른 style은 다른 scale, shift 변수를 가짐!
우선 모든 network는 모든 style에 대해 같은 weight를 가짐 근데 다른 style은 다른 매개변수를 가지게.. ⇒ 잘 되는가보다
이 매개변수들을 또 weighted combination해서 다양한 style이 동시에 녹아들게도 할 수 있음
| 작성자 | 배세은 |
| 소 감 | 이미지의 스타일만 바꿀 수 있는 style trasnfer가 너무 신기했고 gram matrix가 텍스처 표현을 가지게 된다는 것도 정말 기발하다는 생각이 들었다. |
| 일 시 | 2025. 4. 11. (금) 18:00 ~ 21:00 |
| 장 소 | 미래관 429호 자율주행스튜디오 |
| 참가자 명단 | 신수민, 임혜진, 배세은, 김윤희 (총 4명) |
| 사 진 |  |
'세은' 카테고리의 다른 글
| [호붕싸 모각코 7차] 논문 리뷰 - CLLMate: A Multimodal LLM for Weather and Climate EventsForecasting (0) | 2025.04.04 |
|---|---|
| [호붕싸 모각코 6차] 논문 리뷰 - Attention is All you Need (0) | 2025.03.31 |
| [호붕싸 모각코 5차] Image Captioning - Evaluation (0) | 2025.03.24 |
| [호붕싸 모각코 4주차] 컴퓨터 네트워크 - 인터넷의 구조와 네트워크 접근 방식 (0) | 2025.03.22 |
| [호붕싸 모각코 3주차] Semi-Supervised Learning (0) | 2025.03.17 |