
single RGB이미지 받아서 감지된 object들의 set을 output으로 내뱉는다. 각각의 object는 category label과 local정보를 나타내는 bounding box를 갖는다.
여기서 모델이 신경써야 하는 점
1. object의 개수가 사진마다 다르다.
2. 카테고리와 위치 두 개의 output을 가진다.
3. 상대적으로 고해상도의 이미지를 다룬다.
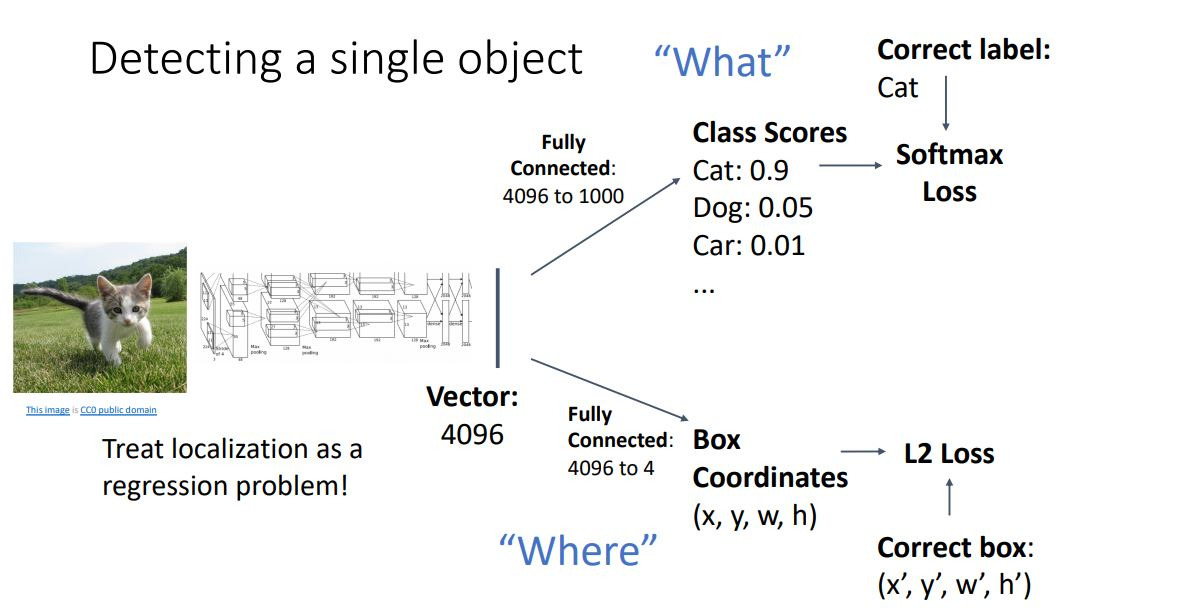
우선 하나의 object를 갖는 이미지가 들어왔다면? 이미지의 feature vector을 뽑고 여기에서 class score들과 box의 위치를 뽑는다. 이 두개의 loss를 어떻게 잘 조합해서 중요도에 따라 잘 tuning해준다. 이러한 loss를 multi task loss라고 한다.

그런데 이미지당 object가 여러개 있을 때는 계산이 많아지기 때문에 object가 있을 법한 set을 먼저 생산해서 그 중에서 실제 object가 있는 지를 평가하는 방식이 있다. 이를 region proposal이라고 한다. 이 중에서 가장 유명한 selective search는 이미지당 2000개의 object proposal을 생산해서 CPU를 통해 처리하게 된다.
이렇게 뽑은 region proposal을 어떻게 인풋으로 넣을 것인가?
1. R-CNN: Region-Based CNN
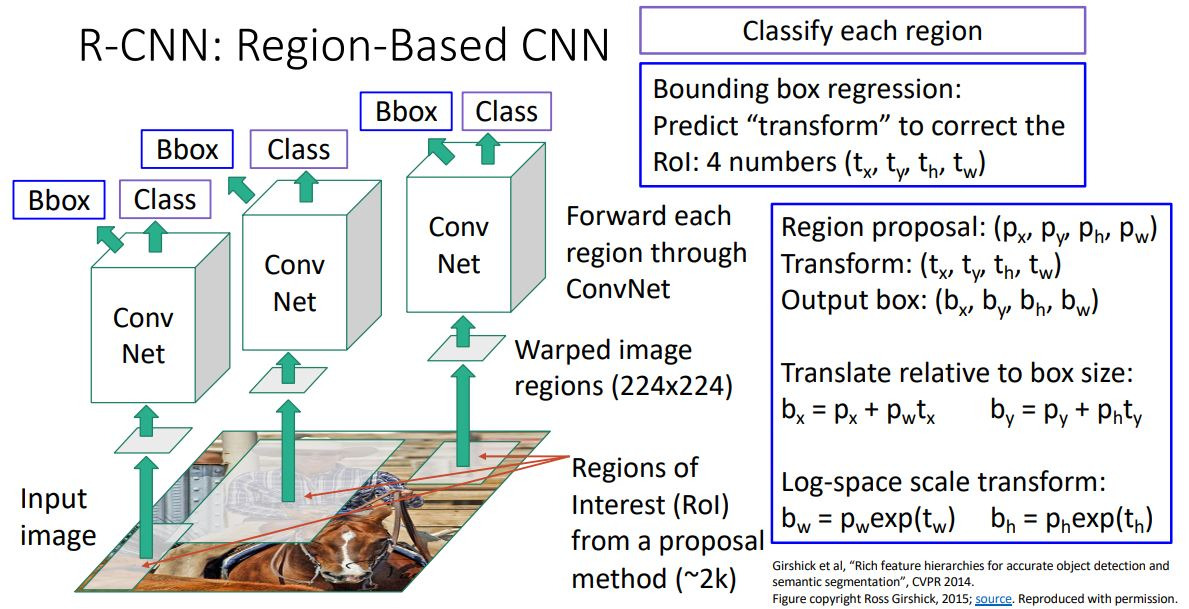
우선 이미지에서 2000개의 RoI(Region of interest)를 뽑아내고, 이때 2000개들은 모두 사이즈가 다를 것인데 ConvNet의 input size는 같기 때문에 224 * 224로 warping 시켜주게 된다.
하지만 이때 selective search를 통한 bounding box추출이 black box여서 학습이 되지 않는다는 문제가 있다. (예?)
이 문제는 Multi-task loss를 사용하여 해결하는데!! B-box를 예측하는 output을 추가한다. 그래서 region proposal box를 좀 transform 시켜서 우리가 원하는 output box를 예측한다. 이는 RoI를 좀 더 fitting하게 바꾸는 과정이다.
ConvNet을 통해 p를 b로 transform시키는 t를 학습하게 된다.
여기까지 R-CNN의 학습 과정이었다. test때는 뭐.. 그냥 이거 쓰면 된다.
다음은 ground-truth box(정답)이랑 prediction이랑 어떻게 비교하는지에 대한 설명이다.

intersection over union이라고 두 box를 비교하기 위한 매커니즘이다.
분모는 합집합이고 분자는 교집합이다. IoU가 0.5이상인 것을 positive window, 즉 정답값으로 사용하였다.
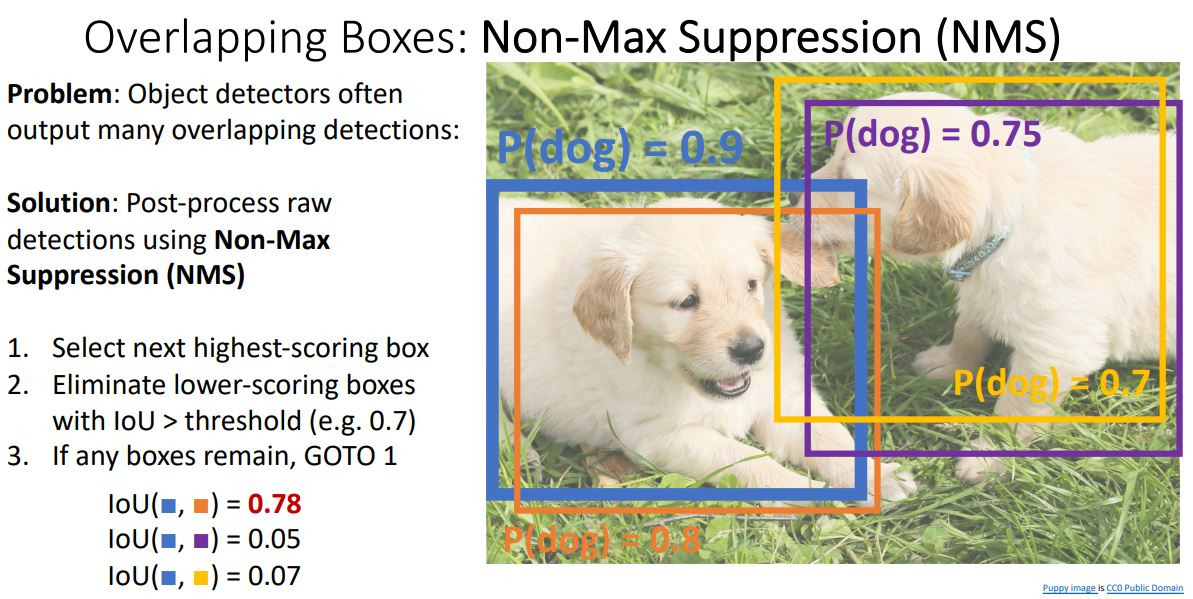
다음은 NMS방식인데, 하나의 object를 인식하는 box가 여러개가 생기는 걸 막아주는 것이다. 먼저 bounding box들의 예측 확률을 내림차순으로 정렬하고, 가장 높은 점수의 box와 낮은 점수의 나머지 box들간 IoU를 계산하여서 설정한 임계값보다 높은 box를 제거하는 방식으로 진행된다. 그런데 엄청나게 많은 object가 있는 image는 엄청나게 overlapping되기 때문에 좋은 결과를 내지 못한다.
이제 object detector이 얼마나 잘 작동할지 평가하는 metric을 설명하겠다.
mean Average Precision이라고 있는데...작동 방식을 보자면 먼저 test-time의 image를 object detector로 forward시킨 후 NMS를 통해 불필요한 detection들을 걸러내고, 각 카테고리에 대한 class score들을 가지게 한다. 이 때 각 class별로 Average Precision을 구하게 된다! 이제 각 detection에서 PR Curve그리는 방법은 ...
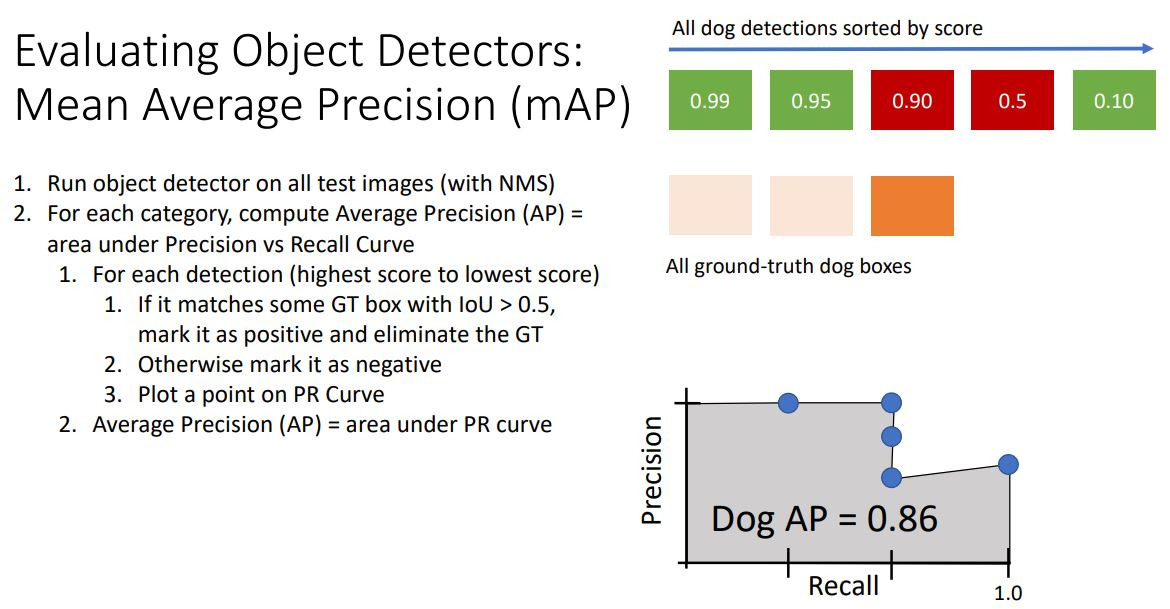
각 dog detection을 높은 score순으로 진행하는데, 정답값과 비교하면서 IoU가 0.5이상인지 판단하며 recall precision 표를 만들게 된다. AP는 0~1사이의 값을 갖는데 1이면 모든 값들이 True Positive라는 의미이다. AP는 Presicion-Recall curve에서 그래프 아래쪽 면적!

여기에서 Precision은 분류모델이 positive라고 판별한 것 중 실제로 positive한 것의 비율이다. 이는 positive로 검출된 결과가 얼마나 정확한지를 나타낸다.
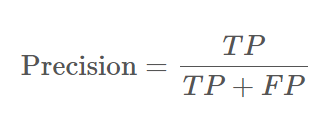
다음은 Recall인데, 이는 실제 positive인 값 중에서 모델이 positive라고 판별한 것의 비율을 말한다. 이는 모델이 얼마나 positive class를 빠지지 않고 잘 잡았는지 나타낸다.
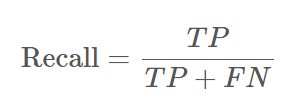
여기에서 ! Precision과 Recall의 조화평균을 사용하는 F1-score이라는게 있는데 이게 무엇이냐!!
우선 조화평균을 사용하는 이유가 뭐냐! precision과 recall이 0에 가까울 수록 F1 score도 동일하게 낮은 값을 갖도록 하기 위함이다. 일반 평균은 1, 0.01이면 높으나 조화평균은 매우 낮게 나온다.

F1-score은 0과 1사이 값이며 1에 가까울수록 분류의 성능이 좋다.
이 둘은 trade-off관계에 있어 decision threshold를 통해 이 관계를 조절할 수 있다. 아 이해했다...
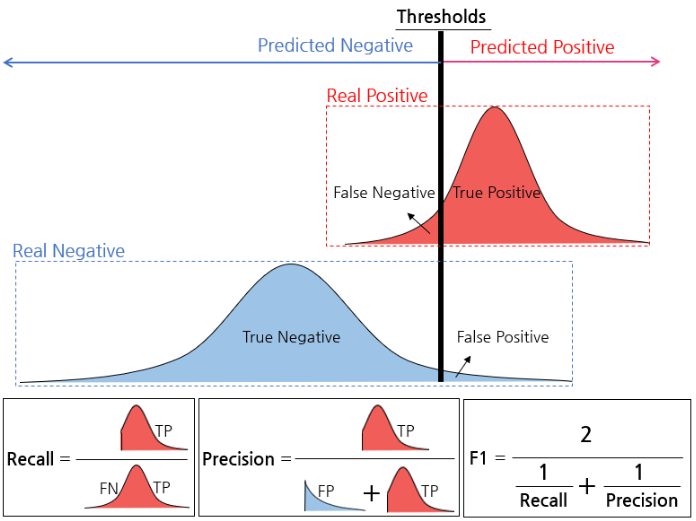
F1-score가 높은 것은 모델이 양성, 음성예측을 잘 하고 있다는 의미이고 AP가 높다는 것은? 알고리즘의 성능이 전체적으로 우수하다는 의미이다.
그리고 class별로 구해진 AP들을 평균내어서 mAP를 구해줄 수 있게 된다.
그런데 이런 R-CNN의 문제점은 2000개의 region proposal을 CNN에 넣어야 하기 때문에 매우 느리다.
따라서 !
2. Fast R-CNN
Fast R-CNN이 등장하였다.
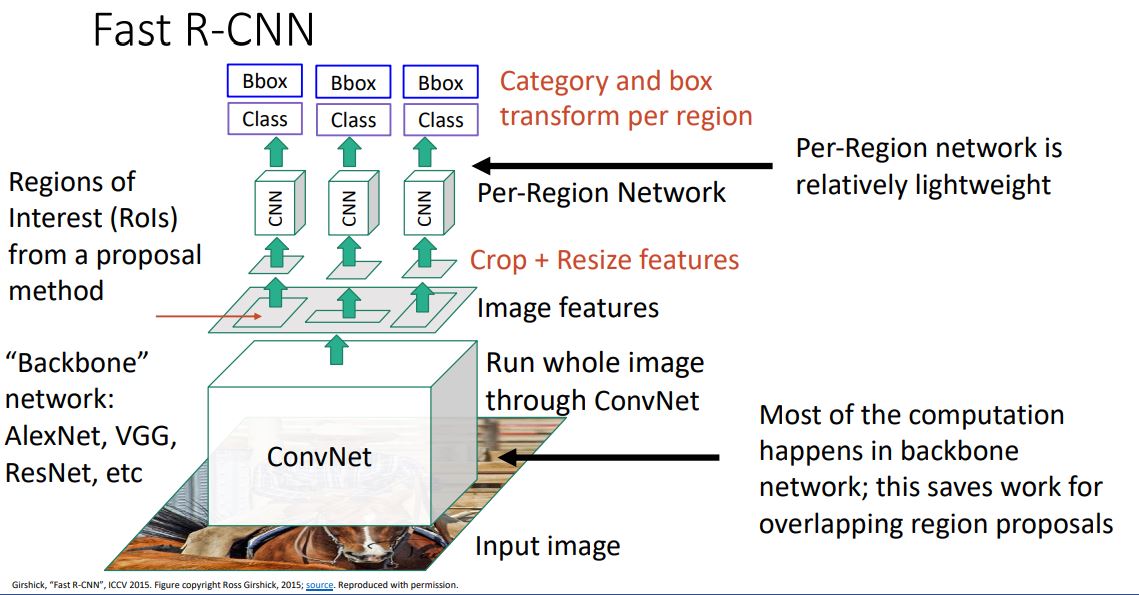
이는 이미지에서 region proposal을 forwarding시키는 것이 아니라 전체 image를 하나의 CNN에 forwarding 시켜서 feature을 뽑아낸다. 이렇게 뽑아낸 feature을 가지고 selective search같은 방법을 통해서 RoI를 뽑아낸다.
또 RoI들을 resize시켜서 각각 CNN에 forward시킨다. 중요한 것은 대부분의 연산이 backbone network에서 이루어진다는 것이다!
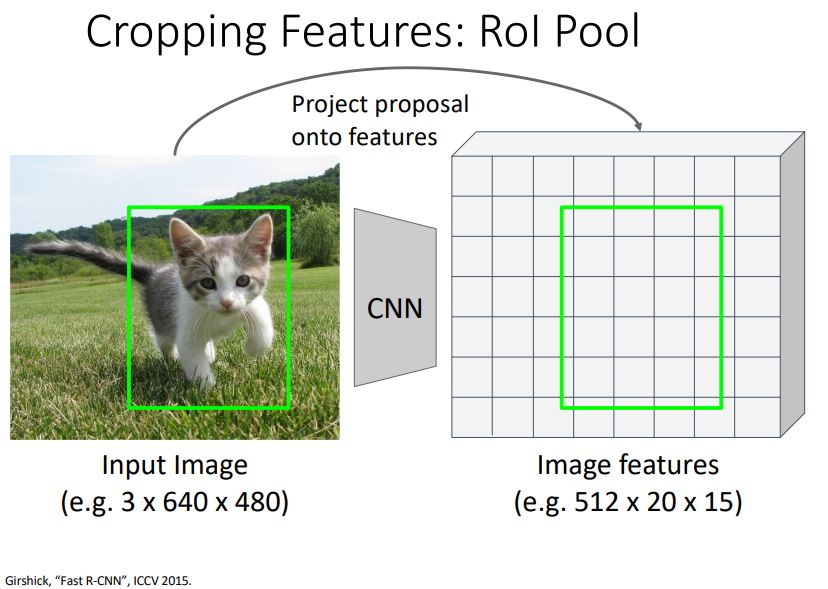
그런데 이때 feature을 cropping하는데 backbone network까지 backprop이 가능해야한다! 어떻게 해야하냐...
RoI Pool을 사용한다. 자 먼저!! Selective Search를 통해 RoI를 찾고! 전체 이미지를 CNN에 통과시켜서 feature map 추출하고! RoI를 feature map 크기에 맞춰서 projection 시키는데! 이때 RoI가 완전히 align되지 않기 때문에 snap시켜준다. 그리고 대충 sub-region으로 나누고 max pooling을 시켜준다. 그래서 input region이 매번 달라도 매번 고정된 size를 갖게 된다. 아 roi pooling을 cnn에 넣기 전에 하는거구나... 이를 하는 이유는 fc layer의 input으로 들어갈 때 동일한 비율로 들어가야 하기 때문에!
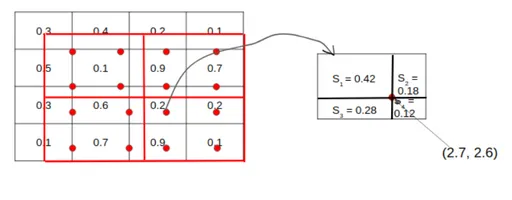
그리고 RoI Align이라는 것이 나오게 되었는데;;.. 왜? snap을 하는 과정에서 정확한 픽셀을 사용하지 않게 된다면 오차가 생기게 되는데, 이는 input image의 원본 위치 정보가 왜곡되고 소실되어서 classification을 할 때는 문제가 안되지만 segmentation처럼 픽셀별로 detection할 때에는 문제가 생긴다. 따라서... 좀 더 정확한 결과값을 얻을 수 있다. -> mask r-cnn에서 사용하나보다.
그래서 이게 뭔데... 하면 그냥 snap시키지 않고 뽑고싶은 feature map크기로 나눈 다음에 각 셀마다 4개의 샘플 포인트를 찾고 bilinear interpolation을 사용한다. 이는 더 정확한 spatial location을 보존하는 것이 가능해졌다.
그런데 이에도 문제가 있었으니.. 이는 selective search를 사용하는 것이 여전히 bottle neck이다. 그래서 CNN을 통해 region proposal을 구하는 방법이 필요하다.
3. Faster R-CNN: Learnable Region Proposals
병목현상이 일어나는 selective search를 제거하고 CNN을 통해 region proposals를 예측해야 한다.
이를 위해서 Faster R-CNN에서는 Region Proposal Network(RPN)을 추가해서 cnn에서 region proposal을 예측할 수 있게 되었다.
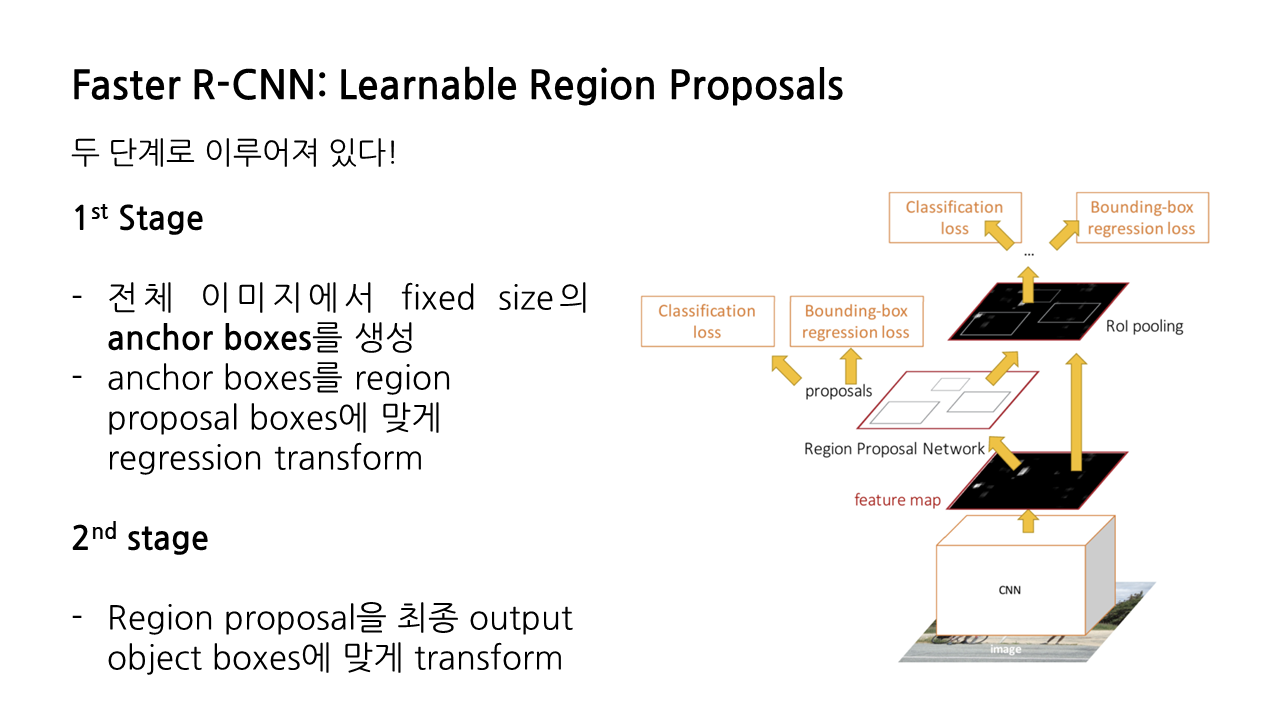
여기에서 RPN말고는 구조가 똑같다! 그냥 feature map에서 RPN으로 구한 box들을 RoI Pooling시키고 CNN에 넣으면 되는 것이다. 근데 RPN이 뭐냐?
RPN은 모든 point에서 고정된 크기의 anchor box를 사용하는 방식이다.
이는 anchor box안에 object가 있는지 없는지를 분류하여 CNN을 통해 학습시킨다. 그냥 얘는 진짜 region proposal처럼 물체가 있냐 없냐만 판별한다. 뭐냐 같은거는 이제 후에 cnn통과해서 알게 되니까.. two category classification -> softmax loss 사용

conv로 나오는거? 픽셀마다 k개의 다른 anchor box들이 나옴 그리고 box transforms는 regression을 위해서 또 box transform을 사용해서 학습한다. label이랑?? 이겠지?? 얘도 쨌든 맞춰주려고?
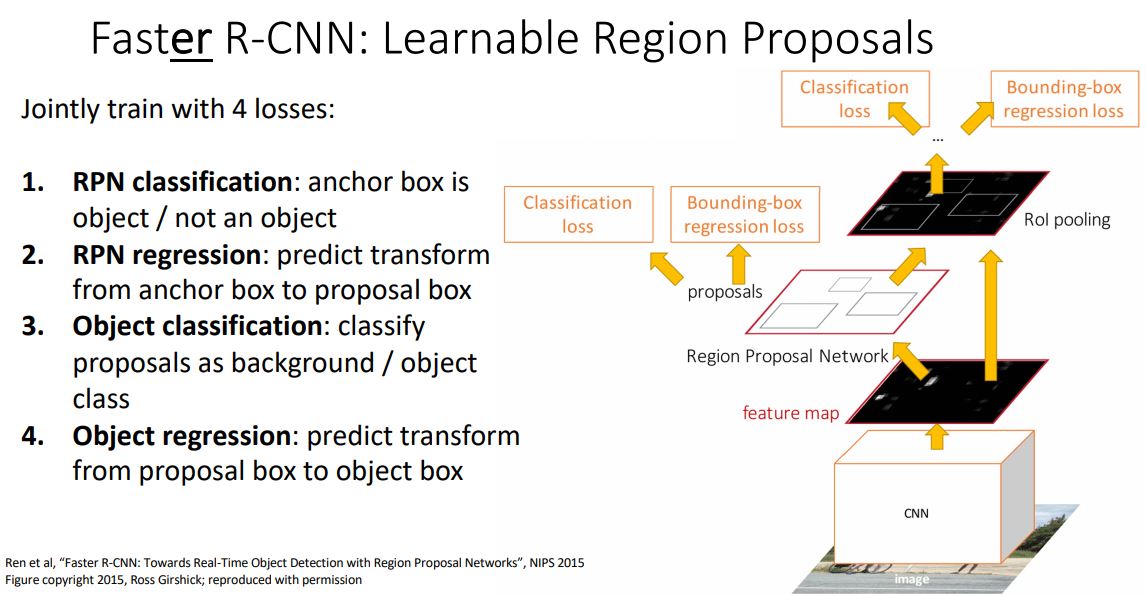
loss 4가지
1. RPN에서 object냐 아니냐
2. RPN에서 anchor box에서 proposal box로의 regression (얘는 어케 되는거??)
3. Object classification에서 classify loss
4. Object regression에서 proposal box에서 object box로의 regression
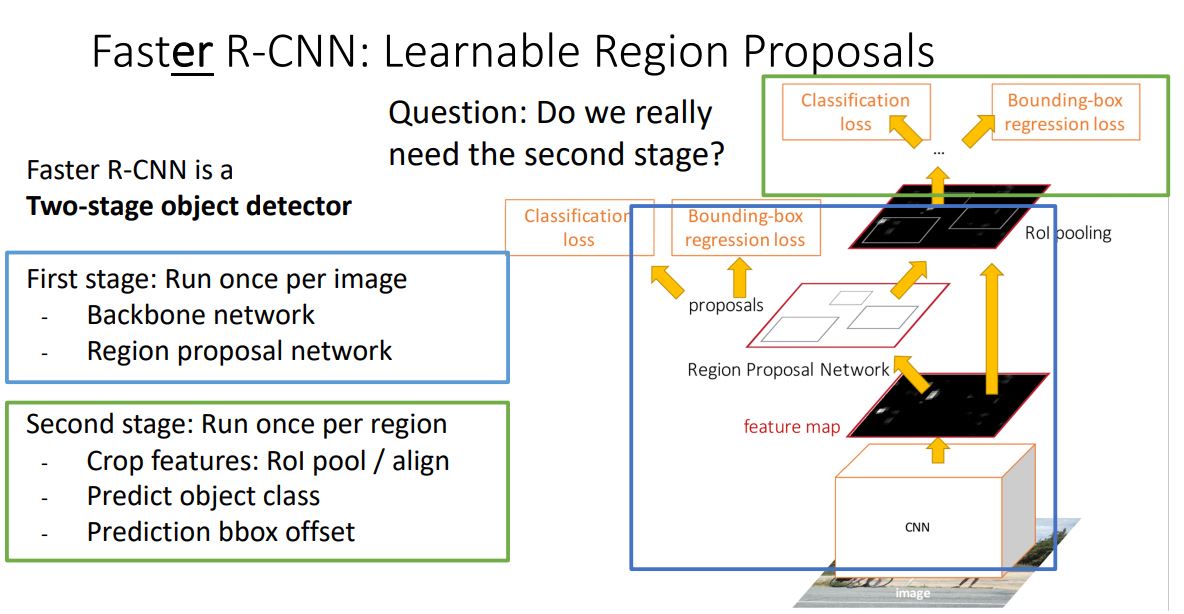
그런데 이렇게 Two stage로 나눌 필요가 있냐?
해서 나온게 Single-Stage Object Detection.
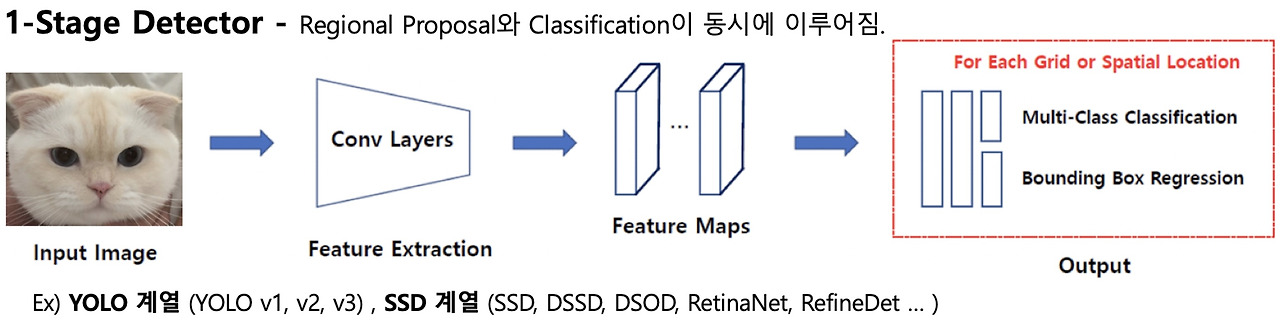
이는 첫번째 스테이지만 사용하고, object인지 아닌지 판단하는 binary classification 대신에 full classification decision을 사용한다. 그리고 regression도 카테고리별로 box transform을 학습하게 된다.
이는 간단하고 추론 속도가 빠르지만 정확도가 더 낮다.
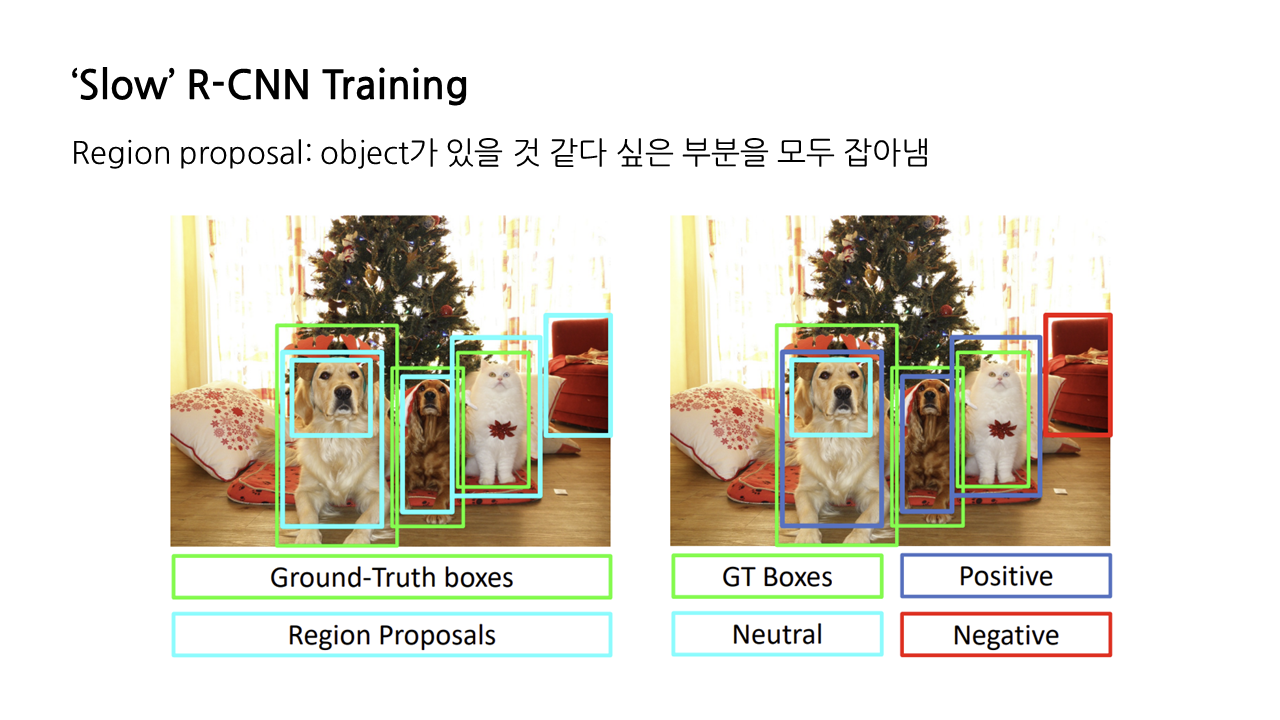
그래서~ positive쌍은 GT와 겹치는 부분이 많은 region proposal이고 negative는 GT와 IoU가 0.3보다 작은 것을 말한다. ㅣㅇ는 배경으로 된다...

뒤에 Semantic Segmentation과 Instance Segmentation은 따로 간단하게 정리해보겠다. 일단 잘게...
일단 object detection은 다양한 object들의 bounding box와 class정보가 나오게 되는 것이고, 이는 다양한 object를 분리할 수는 있지만 픽셀단위로 섬세하게 구분해내지는 못하다.
다음으로 나오는 것은 Semantic Segmentation이다. 이는 이미지의 각각의 픽셀에 카테고리 label을 붙이는 것인데, 객체를 구별하는 것이 아니라 두마리의 소가 붙어있어도 그냥 소 덩어리로 보게 된다.
이게 진행되는 과정은 Fully Convolutional Network가 있다.
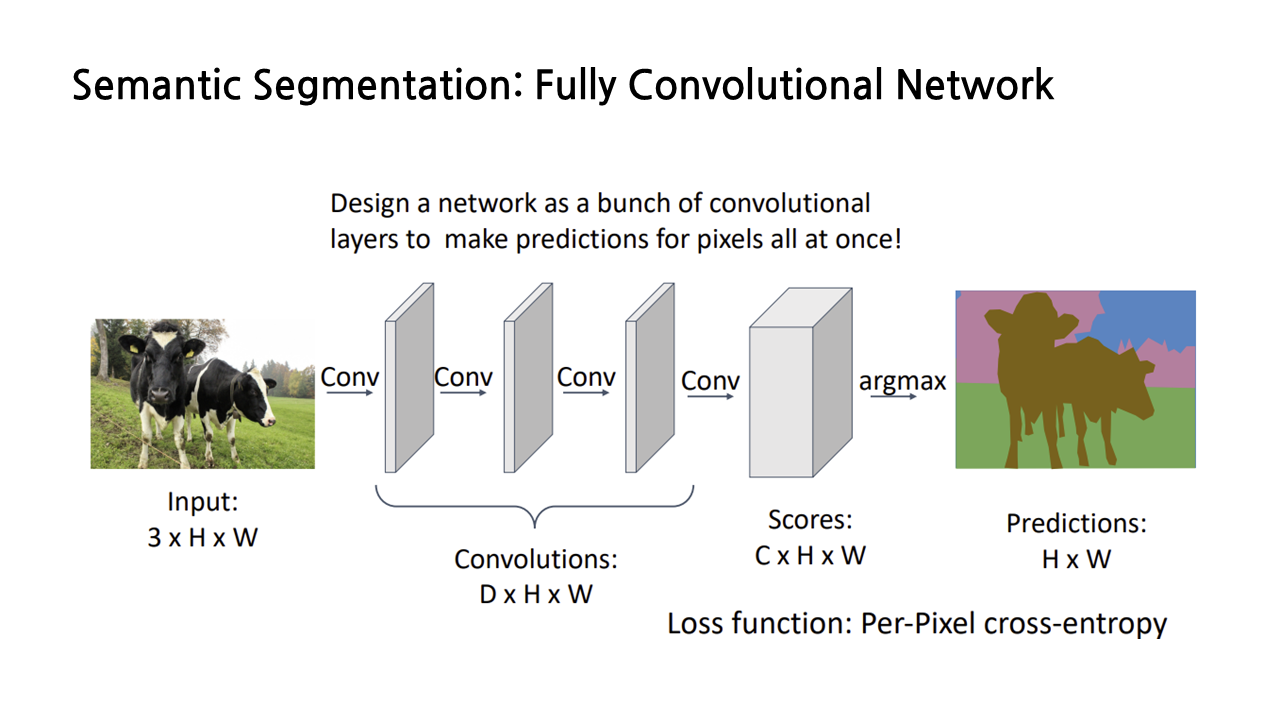
이렇게 conv여러개 쌓게 되면 결과값은 class개수만큼의 channel이 결과로 나오게 되고 따라서 필요한 것이 downsampling이다. 근데 이렇게 하면 layer 개수에 따라서 conv 연산이 비싸기 때문에 down sample 후에 up sample을 진행하게 된다.
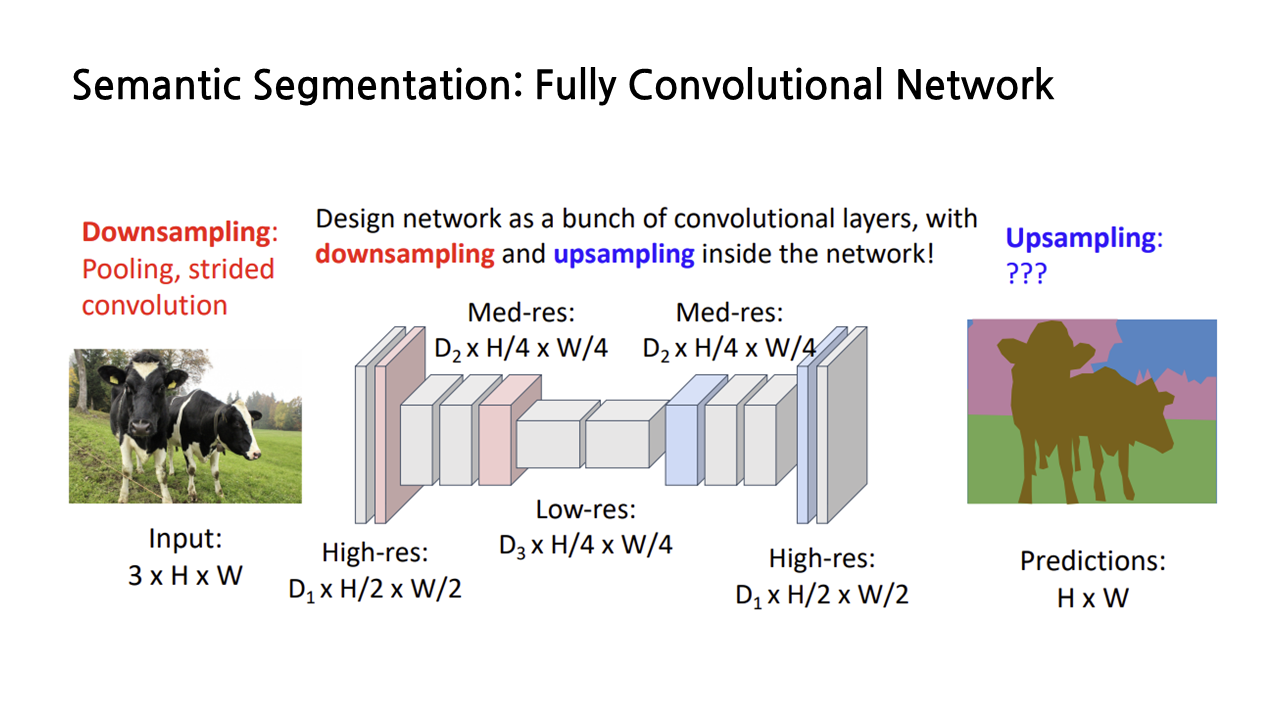
이때 downsampling은 pool을 사용할 것이고 upsampling은 unpool을 사용하게 된다. 이때 0으로 채우거나 bicubic interpolation을 사용하거나... 하는 방식으로 upsample을 진행한다. 이 외에도 Transposed Convolution같이 learnable upsampling 방법도 존재한다. -> 얘 실행 방식은.....
마지막! Instance Segmentation이다. 이는 Object detection이랑 Sementic Segmentation이 합쳐진 방식으로 볼 수 있겠다.
먼저 things랑 stuff가 뭐냐! 하면 things는 instance로 나눌 수 있는 object를 의미하고 stuff는 instance로 나눌 수 없는 하늘..풀...물..같은 것이 속한다.
object detection은 things에 대해서만 detection을 하고 semantic segmentation은 things, stuff모두에 대해 라벨링을 하지만 instance를 세분화 할 수는 없다.
그래서 Instance Segmentation이 나오게 되었는데...이는 things에 대해서만 detection을 한 후 각 things들을 instance로 세분화 하여서 라벨링까지 하는 것이다. 이를 위해서는 mask R-CNN을 사용해야 한다!
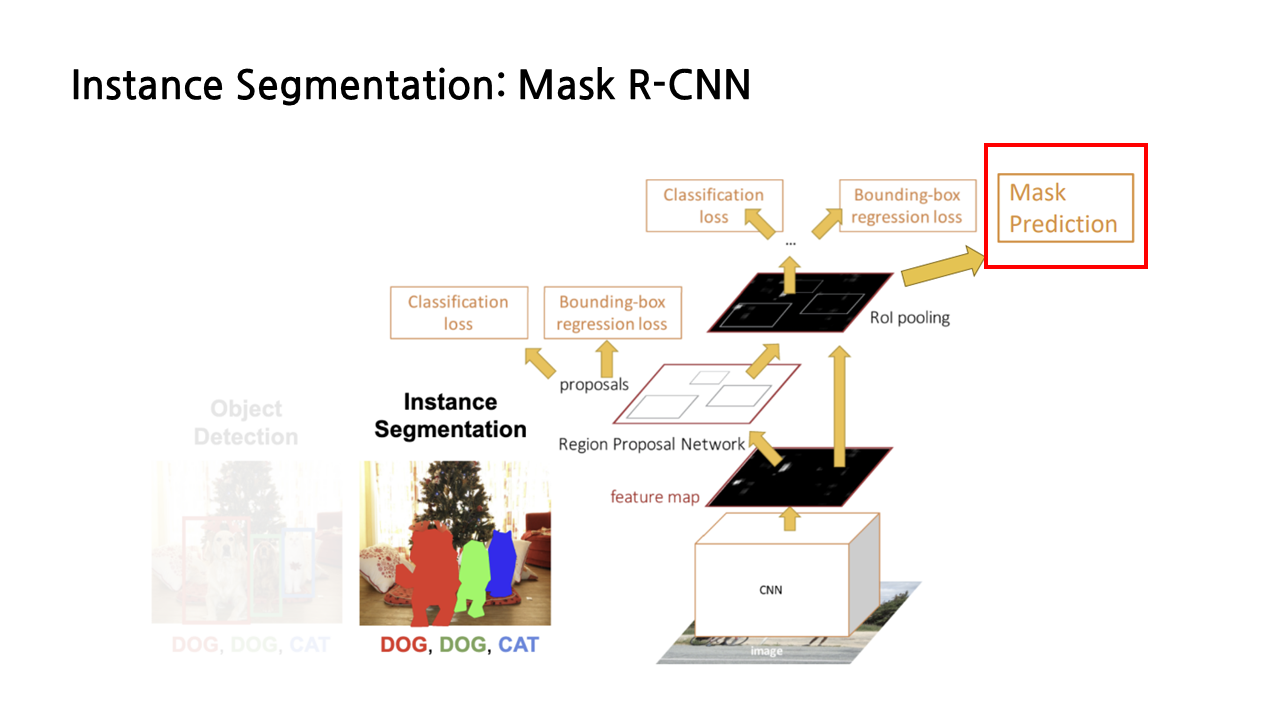
이는 faster R-CNN과 비슷한 작동방식으로 수행된다. 추가된 것은 Mask Prediction 가지가 추가가 되었다. 여기에서 object detection을 통해 추출한 object에 대해서 semantic sementation을 수행하게 된다.
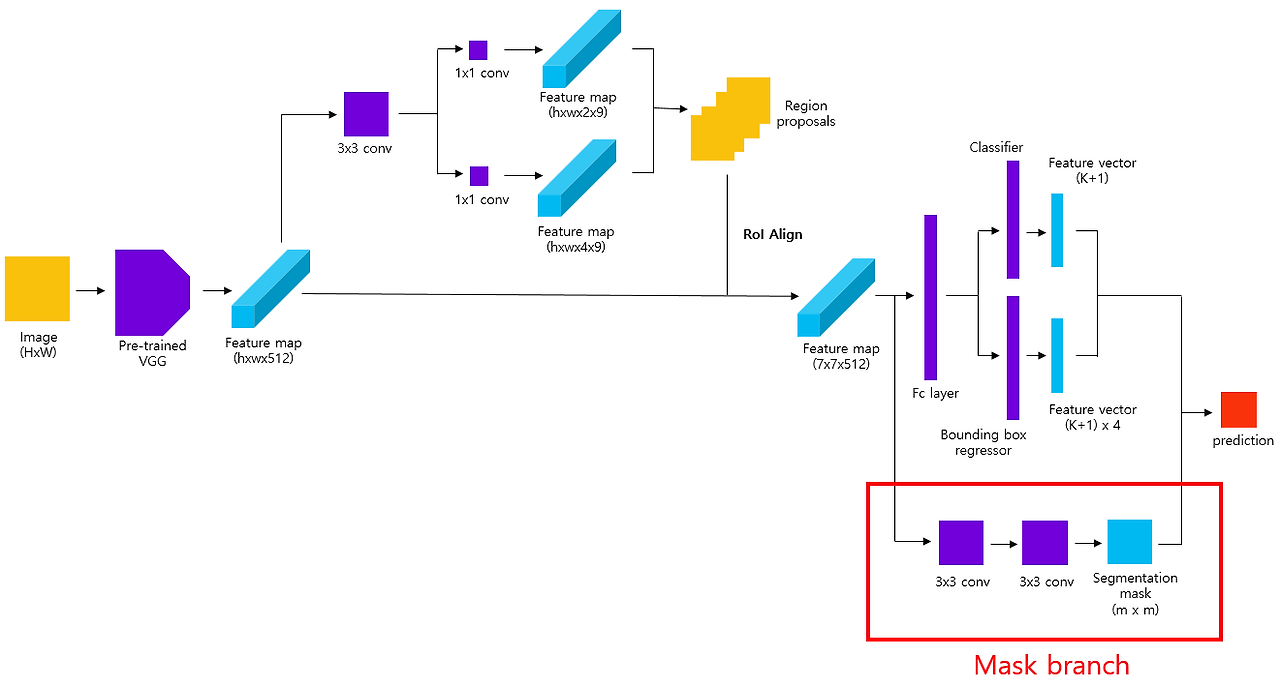
여기에서 보면 우선 RPN으로 region proposal을 찾고, 이에 대해서 RoI align 한 feature map 만든 후에 이제 여기에서 feature map에 conv를 씌우면 segementation을 씌운 이미지가 나타나게 된다! mask branch는 fully convolution으로 fully connected로 한 class label이나 bbox offset에 비해서 객체에 대한 공간 정보를 효과적으로 encode하는 것이 가능해진다.
| 작성자 | 배세은 |
| 소 감 | computer vision의 기초인 object detection과 segmentation을 잘 알게 되어서 뿌듯했다. |
| 일 시 | 2025. 5. 9. (금) 18:00 ~ 21:00 |
| 장 소 | 미래관 429호 자율주행스튜디오 |
| 참가자 명단 | 신수민, 임혜진, 배세은, 김윤희 (총 4명) |
| 사 진 |  |
'세은' 카테고리의 다른 글
| [호붕싸 모각코 11차] CNN Architecture (0) | 2025.05.16 |
|---|---|
| [호붕싸 모각코 9차] GAN (1) | 2025.05.02 |
| [호붕싸 모각코 8차] Visualizing and Understanding (1) | 2025.04.11 |
| [호붕싸 모각코 7차] 논문 리뷰 - CLLMate: A Multimodal LLM for Weather and Climate EventsForecasting (0) | 2025.04.04 |
| [호붕싸 모각코 6차] 논문 리뷰 - Attention is All you Need (0) | 2025.03.31 |