| 작성자 | 배세은 |
| 소 감 | 오랜만에 인공지능의 기반인 CNN의 발전 방법을 살펴보아서 좋았다. |
| 일 시 | 2025. 5. 16. (금) 18:00 ~ 21:00 |
| 장 소 | 미래관 429호 자율주행스튜디오 |
| 참가자 명단 | 신수민, 임혜진, 배세은, 김윤희 (총 4명) |
| 사 진 |  |
2011까지의 ImageNet Challenge 우승자들은 NN이 아닌 손으로 feature을 생성하고, Linear Classifier을 이용해서 우승했다.
2011의 최고 에러율은 약 25.8퍼센트!
2012년부터 처음으로 CNN이 도입되면서 AlexNet이라는 딥러닝이 1등을 해버렸다.
이 AlexNet을 이제부터 자세히 설명해보겠다람쥐
짜잔 그 유명하다는 AlexNet 논문
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
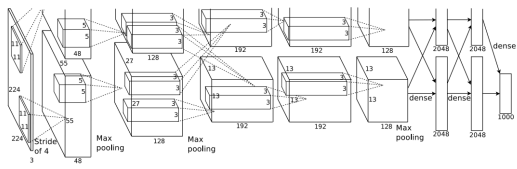
AlexNet의 Architecture
AlexNet의 대표적인 특징은
1. 227 * 227사이즈의 인풋 (논문에 224로 잘못나옴)
2. 5개의 Convolution layer
3. Max pooling
4. 3개의 fully-connected layer
5. ReLU 활성화함수
로 볼 수 있다. (뒤에서 더 자세히 설명하겟슴, 강의 피피티 순서대로 진행)
그리고 Local response normalization을 사용했다고 하는데, 이게 무엇인가..
결론부터 말하자면 후에 batch normalization이 나오면서 잘 사용되지 않는 정규화 기법 중 하나라고 한다.
그래도 뭐냐면!! 생리 신경학 용어로, 한 영역에 있는 신경 세포가 상호 간 연결되어 있을 때 그 자신의 축색이나 자신과 이웃 신경세포를 매개하는 중간신경세포를 통해 이웃에 있는 신경세포를 억제하려는 경향이라고 한다..

헤르만 격자 착시
검정 바탕에 흰 선이 교차하는 지점에서는 흰 선을 인식하는 세포보다 억제된 신호를 보내고, 교차점에서 보내는 신호가 약해지며 덜 활성화되면서 어두운 점이 보이는 현상이다. (신기하죠?)
이 현상을 딥러닝에 적용한 것인데.. 사용하게 된 이유는 우선 알렉스넷은 ReLU함수를 사용하기 때문에 양수 값을 받으면 그 값을 바로 뉴런에 전달한다. 따라서 시그모이드나 탄젠트 활성화같은 최대값이 정해져 있는 함수와 다르게 너무 큰 값이 전달되면 하나의 매우 큰 값이 주변의 값에 영향을 미칠 것이기 때문에(과대적합) 다른 Activation Map의 같은 위치에 있는 픽셀끼리 정규화를 해준다. 그냥...하나만 튀지 않게 해주는 역할인 것 같다.
근본적으로 ReLU를 쓴 이유는 AlexNet과 같은 크기가 큰 망에서는 sigmoid나 tanh함수를 사용한다면 학습속도가 느려진다고 한다.
그리고!! 3GB의 GPU 2개를 병렬화 처리하여 사용하였다. 위 아키텍처에서 보면 3번째 Convolution Layer과 FC를 제외하고 모두 독립적으로 훈련이 진행된 것을 알 수 있다.
GPU 2개 쓴 이유는? 당시의 기술로 최대한 빨리 학습할 수 있는 방법이지 않았을까..
모델 아키텍처
AlexNet의 Layer들을 하나씩 뜯어보자
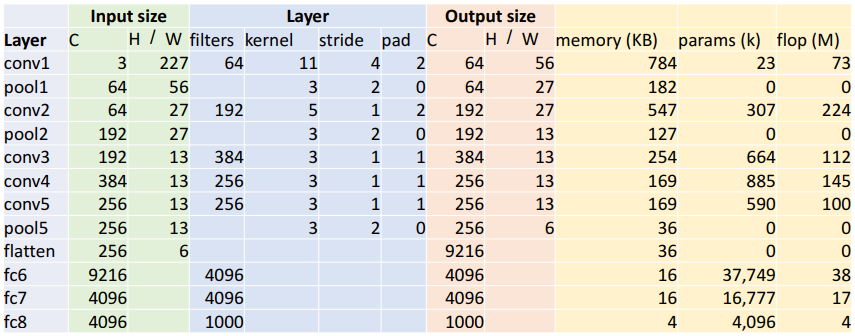
먼저 각 conv층을 통과하면 일단 output의 채널 수는 filter의 수라는 것은 알고 있을 것이다.
그리고 필터의 가로 세로 계산하는 방법은?
W' = (W - K + 2P) / S + 1 이다.
근데 이게 GPU 2개 써서 나뉘잖아요 그래서 엄...아니 피피티 뭐야 input 필터 96해서 GPU에 48개 채널씩 들어가는거 아니야? 허허 Question1
쨋든 그렇게 하고 이제 연산 나옴
output element의 개수 = 채널(깊이) * output 가로 * output 세로이다.
그런데 element마다 4바이트 메모리! (32bit 부동소수점에서)
KB(메모리) = (output of element) * 4 / 1024
파라미터 수 = 필터수 * input의 채널수 * 필터 가로 * 필터 세로 + bias(각 필터마다)임!
flop(곱셈, 덧셈 계산 수) = (output element의 수) * (element마다 계산 수)
일단 conv1지날 때 이렇게 계산 하고 다음에 ReLU를 지난다.
(ReLU는 Flop이 없다고 한다.)
* Flop은 Floating Point Operations인데, 모델이 얼마나 Computing자원을 필요로 하는지를 나타낸다. 이는 덧셈과 곱셈이 한 사이클에 한 번에 수행되므로 횟수를 헤아릴 때 둘 다 합쳐서 하나의 연산으로 봐야 한다.
이제 pool1을 지날 것이다. 여기서 특이한 점은 pool의 kernal != stride라는 점!
이것의 명칭은 Overlapping Pooling이다.

Pooling stride를 다르게 하는 방식
이걸 쓰는 이유를 찾아보니 일반화 성능을 향상시키고 오버피팅 방지를 하는 기능이 있다고 한다.
정보의 손실을 더 줄이기 때문에 학습 데이터에 민감하게 반응할 확률이 더 줄어든다.
pool 지나고 output size는 W' = floor((W - K) / S + 1)이란다. floor으로 반내림(?)을 하게 된다. (이 이유도 찾아보자)
그리고 Pooling layer은 학습 가능한 변수가 없다! (그냥 평균 때리거나 최대 뽑기만 해서)
flop수는 M단위로 하면 0.4로 매우 작다. 컨볼루션 레이어에 비해서. 부동 소수점 연산 비용이 거의 들지 않는다고 한다.
이렇게이렇게 conv지나고 ReLU지나고 pool지나고를 반복한 후 이제 flatten을 시킬 차례가 왔다.맨 마지막에 하는 절차로 MLP(fully connected)에 지날 준비를 하는 것이다. 이거 output 계산은 easy하다. 그냥 Cin * H * W 하면 된다. 한 줄로 쭉 펴주는 것이다.그러나 이제 파라미터수는 big..
top 5 error이 무엇인가
flatten시키고 fc에 넣는다. 9216 -> 4096 -> 4096 -> 1000 순으로 size변환이 일어난다. (사이사이 ReLU!)마지막에 1000은 category 개수로, 카테고리 분류를 위해 activation function으로 softmax를 사용한다고 한다. * 왜 fc를 여러개 쌓느냐? 9216 -> 1000으로 하면 안되냐? - cnn은 주로 이미지의 저수준 특징(엣지, 패턴)을 추출하는데, fc는 이 저수준 특징을 조합하여 고수준 추상적 특징을 학습한다. 복잡한 패턴이나 객체에 대한 추상적인 정보를 학습할 수 있다.

각 레이어의 매개변수와 FLOP수
대부분의 메모리는 초반의 컨볼루션 레이어에서 많이 사용한다.
초기 레이어에서 입력 이미지의 고수준 특징을 잘 포착하기 위해 높은 공간 해상도(spatial resolution)이 필요해서, 대용량의 activation map이 생성되고, 이게 메모리에 저장된다고 한다.
그런데 fully-connected layer은 입출력 모두 연결시키는 가중치가 있어야 하므로 매우 많은 파라미터가 있어야 한.
(근데 왜..메모리는 conv에 비해서 많이 작은가요.,?)
그리고 높은 해상도, 많은 수 필터가 있는 Convolution Layer에서 많은 연산이 일어난다.
여기까지 AlexNet이었는데..질문
1. 중간중간 두 GPU가 연산 결과 섞을 때 어떤 방식으로 섞냐
과적합 방지 기법
1. 이미지 좌우반전
2. fully-connected layer에서 일부 뉴런을 꺼버리고 학습시키는 과정
다음은 ZFNet이다.

ZFNet의 Architecture
ZFNet은 알렉스넷에서 발전된 형태이다.
GPU를 하나만 쓰고 일부 layer의 하이퍼 파라미터를 조정하였다.
conv1에서 stride를 4 -> 2로 변경하고 필터사이즈를 줄였는데, 이는 극단적 고주파, 저주파 정보만 남겨 중간 주파 정보가 남지 않는게 문제라고 생각해 바꾼 결과라고 한다. feature가 더 많은 정보를 가지게 해서 classification성능을 높였다고 한다.
conv3, 4, 5에서 더 큰 필터를 사용하였다.
필터 개수도 늘리고 stride도 줄여서 연산을 늘려서 정확도를 그냥 높였다!
visualizing 기법을 사용했는데, 중간 layer의 feature map을 시각화 할 수 있게 하여 더 좋은 모델 구조를 고안했다고 한다.
어떤 input pattern이 해당 activation을 유발했는지 input pixel space로 매핑시켜 해석을 해주는 것인데,
conv -> relu -> pool의 정확히 반대 과정으로 수행한다고 한다.
역연산에서 가장 문제가 되는 부분은 max pooling인데 반대로 할 땐 어느 구역에서 해당 자극이 왔는지 모른다.
그래서 그 위치 또한 알 수 있게 한다고 한다.
input image가 맥락만을 파악하는지 아니면 올바른 특징을 보고 판단하는지 이미지의 일부를 가리고 feature map의 활성 정도를 확인하는 과정을 거쳤다.
다음은 2014년에 나온 VGG이다.
지금까지는 8 layer이었다가 이제 19 layer의 등장이다

VGG design
이전까지는 모두 시행착오를 거쳐 만든 아키텍처엿는데 이제부터는 원칙이 있게 만들기 시작하였다.
1. 모든 conv는 3*3에 stride는 1, padding도 1
2. 모든 max pool은 2*2에 stride도 2
3. pooling 한 다음에 채널 수 두 배 증가
왜 뛰어날까..
먼저 1에 관련되어서 말 해보자

먼저 구조를 보면 각 stage마다 conv가 2개씩 등장하고 마지막 2 stage만 3 or 4개의 conv가 등장하도록 만들었다.
원래 conv필터가 5*5였던 것을 3*3을 2번 사용하였는데 이런 방식으로 하면 좋은 점!

필터 크기에 따른 연산 수
연산 수가 확 줄어든다. 두 방식 모두 receptive field가 5*5인데 말이다!
그리고 사이사이에 activation function넣어주면 더 좋아지겠지?
이렇기 때문에 일단 커널사이즈가 하이퍼 파라미터였던 것이 3으로 고정되게 되었다.
그리고 모든 max pool은 2 * 2 stride 2이다.

pooling layer 전 후 정보
pool하고 난 후가 메모리는 절반 차지하는데 파라미터는 4배 늘어나고 flop수는 같다는 것을 볼 수 있다.
더 뛰어난 성능을 더 적은 비용으로 얻을 수 있다!
(데이터 배치가 뭐냐.. 배치분할한다고 적어놨는디..)
이러한 VGG는 AlexNet에 비해 훨씬 거대한 모델이었다! 연산량도 많고.. 메모리도 많이 차지하고..
이번에 소개할 모델은 2014년에 나온 GoogLeNet이다. (VGG와 같은 년도)
GoogLeNet은 큰 네트워크가 좋지만! 더 효율적으로 만드는데 중점을 두었다.

GoogLeNet Architecture 길쭉하당
ㅇㅒ는 공격적인 다운샘플링을 시도했다고 한다.
원래 대부분의 계산은 시작에서 많이 수행되자나요? 그래서 conv계산 줄이려고 빠르고 가볍게 초반에 만들었다고 함니다.
먼저!! 기이일쭉하게 잇죠 거기까지 과정이 224 -> 28로 다운샘플링 하는 과정이랍니다. 이렇게 하면 좋은 점이 뭐냐면 더 더 많은 계산을 할 수 있다는 점이겠죠. (물론 채널 수는 늘어남)
근데 여기서 또 궁금점.. 채널 수를 늘이는게 가로세로 큰 것 보다 계산량이 줄어드나??
구글넷 특징
1. Inception Module

딥러닝 네트워크의 성능을 높이기 위해서는 layer와 channel수를 늘려야한다. 하지만 기존의 Dense(weight들의 대부분이 0이 아닌 값)에서 크기 키우면 오버피팅, 연산량 증가..등 문제가 발생한다.
그래서 깊게 만들지만 파라미터 수를 줄이기 위해 sparse하게(weight 대부분이 0인 형태) 큰 구조로 만든다.
그런데 이러한 구조는 연산 효율이 떨어진다. 따라서 상관도가 높은 애들끼리 묶어서 dense한 형태로 만든다.
위 개념을 연구하기 위해 Inception Module구조가 시작되었다고 한다.
filter concatenation하는 방법? 3 * 3 max pooling..하는 방법..?
먼저 1 * 1 conv layer을 사용해서 차원의 수를 줄이는 방식으로 연산량을 조절하였다.
그리고 1 * 1, 3 * 3, 5 * 5와 같이 다양한 스케일에서 conv 연산 진행을 통해 효율적으로 특징들을 뽑아냈다.
3 * 3이랑 5 * 5랑 차이...receptive field
max pool을 먼저 하는 이유 -> 여러개를 다양하게 뽑아보자.. 해상도를 낮추는 작업?? 그 이건 채널수를 못맞춰주니까 pool을 먼저 해준다고 하긴 하는데

GoogLeNet의 output size
구글넷은 fully connected를 위해 flatten을 사용하지 않았다. avarage pooling을 통해서 그냥 7 * 7의 평균을 1개 픽셀로 내버렸다. 이렇게 공간정보를 파괴하였다. 이는 fully connected layer의 크기를 크게 줄이게 되었다.
근데..그냥 이렇게 해도 되나요..? 이 부분 더 알아보고 시픈데..말이 잘 안돼..
2. Auxiliary Classifiers
모델의 중간중간에 avg pooling layer과 fully connected로 구성된 classifier을 말한다. (위 사진에서 옆에 갑자기 가지처럼 튀어나온 부분!)
이는 Batch Normalization 이전에 나온 방식으로 batch norm이 생기기 전에는 10개 이상의 레이어 네트워크 훈련을 하지 못했다. 이유는 레이어가 깊어질 수록 경사가 사라지거나 급격히 커지는 문제가 있었다. 이를 해결하기 위해 네트워크 중간중간에 auxiliary classifier을 붙임으로써 추가적인 back prop을 발생시켜서 더 gd가 쉽게 전파되도록 한다.
세 개의 클래스 분류 점수를 결과적으로 내는데..
실제 테스트 할 때는 사용하지 않는다..?

모델의 발전...
이제 2015년이다.... 이 해는 batch normalization이 나왔던 해로 22보다 훨씬 깊은 152개의 레이어를 쌓을 수 있게 되었다.
다음은 ResNet!!
레이어가 깊어질 수록 좋은 성능을 내야 하는데 더 나빠진다? 그러면 optimizer의 문제이겠다.
Residual Network는 ResNet인데, 이는 네트워크에 층을 추가하면서 더 얕은 모델을 모방하게 하는 방식이다.
레이어가 56개인 모델과 20개인 모델이 있다고 할 때 첫 20개의 레이어는 통째로 복사하고 나머지 레이어는 identity function역할을 하게 한다. 그러면 20레이어 모델의 성능은 보장이 된다는 말인데, 그러지 않았다면 optimization에서의 문제라는 것이다.

weight layer를 통과한 F(x)와 weight layer들을 통과하지 않은 x의 합의 구조를 Residual Block이라고 한다.
이 때 남는 레이어를 identity function의 역할을 하도록 하는데, 밑에는 더 쉽게 수행할 수 있게 하는 방식이다.

두 번째로 ReLU가 적용되기 전에 add gate를 통해서 X와 conv의 결과를 더하였다.
이렇게 하면 두번째의 conv layer에서 0으로 나오면 항등식 계산하는거랑 똑같이 되는데, 이는 심층 네트워크가 복사하는 것을 더 쉽게 만들 수 있다.
일단 오버피팅이랑 기울기 소실 문제를 해결했다고 한다.
역전파 할 때 역방향에서 기억하는 코드!! 있잖슴 그거랑 비슷한거 말하는 것 같긴 한데.. 그레디언트 단축하고 깊은 레이어에 정보 전파 개선하는데 도움이 된다?? 먼저 타겟값 y를 입력값 x로 매핑해서 H(x) - x를 최소화 하는 방향으로 학습이 진행되는데, 이를 residual(잔차)라고 한다. 그런데 H(x)가 x가 되도록 Residual Learning으로 학습해도 기울기 소실 문제가 해결되지 않아서? 최소 기울기로 1을 갖게 하기 위해 미분값 1을 갖는 X를 더해서 기울기 소실 문제를 해결한다.. 그런데 Shortcut은 입력값을 출력값에 더해주기 위한 것으로..활성화 함수 이전에 시행된다..

ResNet의 Architecture
64 -> 128로 넘어가는 부분은 어떤 식으로 바뀌는 것인가 숫자 의미 논문 찾아봐
1 * 1conv사용..?
ResNet은 이러한 residual block과 VGG의 디자인(3 X 3 conv, stage, 채널 2배)랑 비슷함
각 block은 residual block이다.
그리고 초반에 다운샘플링 크게 하고 fully connected줄이는 방식(global avg pool)사용 -> GoogLeNet 비슷함
어쨌든!! 이러한 기법들을 사용해서 ResNet에서는 input size와 각 stage에서 block수만 조절하면 상대적으로 적은 Flop과 error이 낮은 모델을 만들 수 있다!!

어때!! GFLOP적은데 error 더 낮지!!

더 깊은 모델 만들 때 Residual block
그리고 기본 Residual block은 왼쪽과 같지만, 더 깊은 모델을 만들 때에는 오른쪽과 같이 Bottleneck Residual block으로 만든다.
첫 번째는 기본 블록보다 4배 많은 공간 채널을 가진 입력 텐서가 들어올 수 있고, 처음 레이어는 채널을 1/4로 줄이고 마지막에 다시 4배로 늘림 -> 원래 크기로! 왜냐하면 계산 줄이려고..and 더 많은 nonlinearity

자 Block type 잘 보고 GFLOP이랑 error잘보세요 Bottle Block이랑, 레이어가 깊어질수록 good~ 이 차이를 확인하세요구르트
이러한 ResNet은 ImageNet Challengee말고도 다양한 대회에서 높은 성능을 보엿다. 여러 분야에서 baseline이 되엇다!
또 Residual block에서 batch normalization과 relu의 순서를 변경하고 activaion func을 add node 전에 넣으면? error이 줄어든다~
근데..실제로는 잘 안쓰인다..
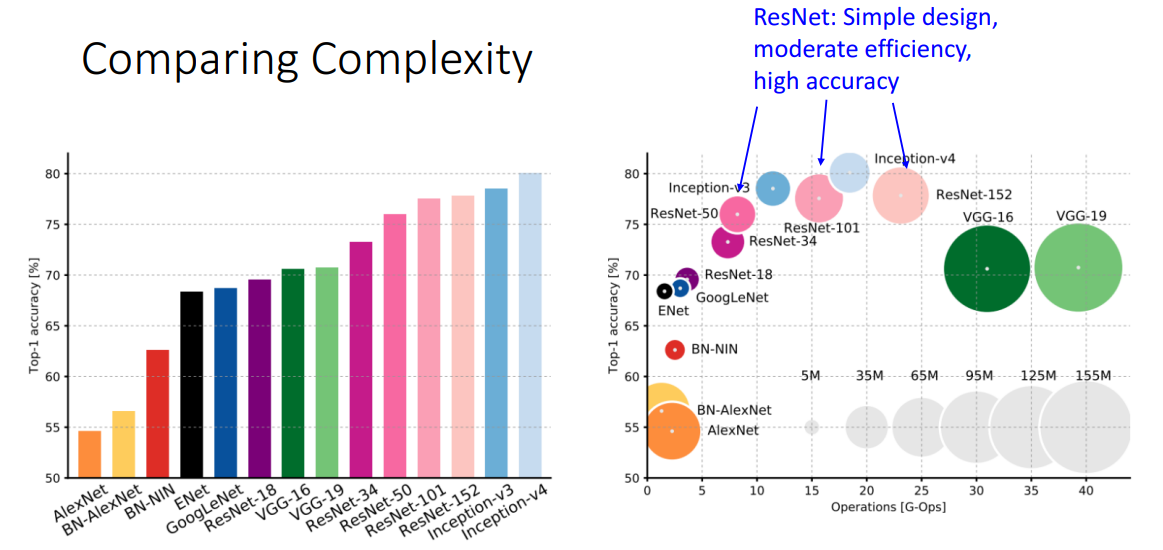
성능 비교
성능을 비교한 거신데..
x축은 FLOP이고 y는 정확도와 크기이다.
- VGG는 많은 메모리, 많은 계산, 성능 별로
- AlexNet은 적은 계산, 많은 파라미터, 성능 낮음
- ResNet은 적은 파라미터, 적당한 계산, 높은 정확도
2016년의 winner model은 지금까지 나온 모델의 앙상블! 혁신적 시도 X
그리고 ResNet을 개선하려는 시도 -> ResNeXt
모델 이름 매번 참.. 참신하게 잘 짓는다

bottleneck block을 G만큼 병렬처리하기!
여기에서는 1 X 1 Conv로 채널 축소를 할 때 c만큼 축소를 하였는데, 이 때 9Gc^2 + 8GCc - 17C^2 = 0이라는 Flops을 구하는 방정식을 통해서 임의로 C와 G를 정하고, 기존의 bottleneck residual block과 동일한 연산이 수행되는 c로 정한다고 한다.
그리고 Grouped Convolution도 있는데, 이거는 Group의 수만큼 GPU를 병렬적으로 사용하는 것인데, 채널을 GPU 수만큼 분리해서 학습을 따로 진행하는 방식이라고 한다.
이렇게 하면 동일 비용으로 더 나은 성능이 나타난다고 한다.
왜...?그리고 Grouped convolution 빼먹엇네
이렇게 이렇게 2017년에는 또 다른...Squeeze-and-Excitation Networks (ResNeXt-152-SE)라는 모델이 이겼다.
이는 말 그대로 짜내는 연산이라고 한다.
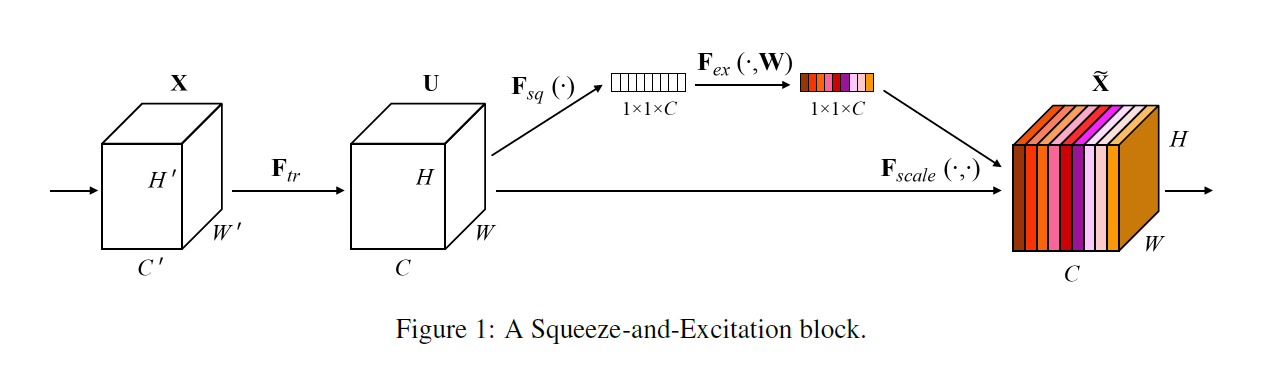

그럿타. 일단 Squeeze할 때는 GAP으로 global spatial information을 channel descriptor로 압축시킨다. 정보 압축을 위해서 H X W X C 크기를 1 X 1 X C크기로 만들었다고 한다. 머 다른 방법론을 써도 된다고 한다.
그리고 Excitation을 할 때는 채널 간 의존성을 계산한다. Fully connected layer과 비선형함수를 조절하는 것으로 계산하는데, 아악 이 부분은 나중에 좀 더 정리해볼게요 global context가 뭐냐 -> 여기도 안할래
이렇게 2017년에 대회가 끗!!!!(드디어 내 정리도 거의 끗!!!)났다고 한다.
그리고 이제 후에도 Densely Connected Neural Network이다.
각 레이어가 이전 레이어의 모든 레이어와 연결된 밀집한 구조를 가지는 네트워크 디자인 패턴을 나타낸다.
input X를 전달하여 더하는 것이 아니라 Concat을 하는 방식이라고 한다.
여기도 더해라 -> 안할래
또!! MobileNets는 Tiny Networks인데 이전과 다르게 높은 성능보다는 매우 적은 계산으로 괜찮은 성능을 내는 모델을 만들었다. conv를 2개로 쪼갠 것!
여기에도 Pointwise Convolution이랑 Depthwise Convolution이랑 뭔지 추가하기
모바일넷 시작할게여
모바일 장치와 같이 리소스가 제한된 환경에서 효율적인 계산을 위해 설계된 경량 심층신경망이며, 기존의 CNN에 비해 훨씬 가벼운 모델이다.
1. Depthwise separable convolutions
대조적으로 이는 input feature map의 각 채널에 독립적으로 필터 적용이 되어서 output feature map을 생성한다.
채널마다 다른 필터가 적용됨! -> 출력 채널의 수는 입력 채널의 수와 동일하다. (필터 수 = 출력 채널 수)
2. Pointwise Convolutions
1x1 conv임! 연산량을 줄이는데 효과적이고 필터 수를 줄여서 차원 축소를 할 수 있습니다.

여기에서 pooling을 안쓰고 conv를 stride를 2로 잡아서 차원 축소와 정규화 효과를 낸다고 함 -> 계산 비용을 줄이고 공간 해상도를 유지하며 네트워크를 정규화 하기 위해 stride 2를 사용한다고 함
'세은' 카테고리의 다른 글
| [호붕싸 모각코 10차] Object Detection, Segmentation (1) | 2025.05.09 |
|---|---|
| [호붕싸 모각코 9차] GAN (1) | 2025.05.02 |
| [호붕싸 모각코 8차] Visualizing and Understanding (1) | 2025.04.11 |
| [호붕싸 모각코 7차] 논문 리뷰 - CLLMate: A Multimodal LLM for Weather and Climate EventsForecasting (0) | 2025.04.04 |
| [호붕싸 모각코 6차] 논문 리뷰 - Attention is All you Need (0) | 2025.03.31 |